
みなさんこんにちは、X(クロス)イノベーション本部 ソフトウェアデザインセンターの鈴木です。
データベースにAmazon DynamoDBを採用しているWebアプリケーションを、Amazon RDSを採用したWebアプリケーションにリプレイスしている際に、データ移行で苦戦したことを記事に残します。
背景
従来のアプリケーションでは、データベース層にNoSQL型のデータベースであるDynamoDBを採用していました。
しかし、利用ユーザーが増加してパーティションキー以外での検索要件が出てきたことで、フルスキャンをせざるを得ないケースがたびたび発生したためレスポンスタイムやコストの問題が発生していました。
以上のことから、NoSQL型のデータベースより柔軟に検索が可能な、RDB型のデータベースであるRDSに移行することとなりました。
実現したいことと、苦戦したこと
実現したいこと
移行元のDynamoDBテーブルからデータをエクスポートし、移行先のアプリケーションのデータベース(PostgreSQL)のテーブル定義に基づいてデータを変換します。最終的には、RDSへデータをインポートすることを目指します。
データの変換・移行には、AWS GlueやAWS DMS(Database Migration Service)などのAWSサービスを利用することもできます。今回は、開発環境でデータの一部を使いたかったこともあり、開発環境でTypeScriptを用いて変換します。
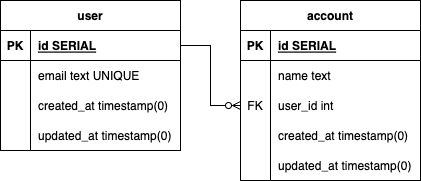
アプリケーションとテーブル定義
アプリケーションは、Next.js × Prismaを用いて実装しています。
データベースにはPostgreSQLを採用しており、記事用に簡略化した移行後のテーブル構成は以下のとおりです。
userテーブルとaccountテーブルがあり、userテーブルのidを外部キーに、accountテーブルとリレーションを築いています。
苦戦したこと
DynamoDBからエクスポートしたデータを変換してデータベースにインポートする過程で、SERIAL型であるuserテーブルのidはレコードが作成されるまで確定しません。accountテーブルにレコードを作成する際に、accountテーブルの外部キーであるuser_idは、userテーブルのレコードを作成後にuserテーブルから取得しなければなりません。
また、Webアプリケーションのソースコードや、アプリケーションが参照しているデータベースのスキーマにはなるべく手を加えないようにしたいです。
解決方法
要点
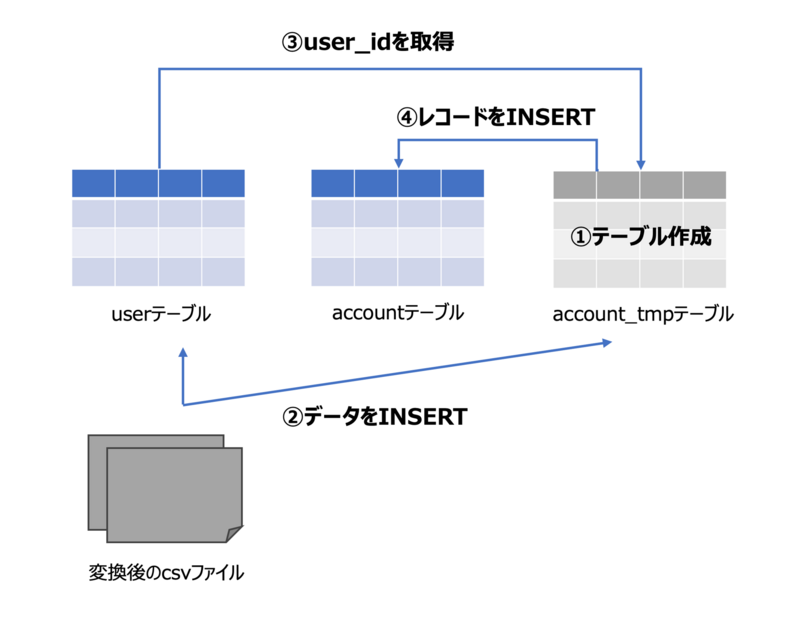
今回は次の流れで解決しました。
①accountテーブルとは別に一時的なaccount_tmpテーブルをデータベースに作成する。
②userテーブルとaccount_tmpテーブルに変換後のデータをINSERTする。
③userテーブルからaccount_tmpテーブルのレコードに対応したuser_idを取得して、account_tmpテーブルのレコードをUPDATEする。
④account_tmpテーブルからaccountテーブルにINSERTする。
以降、詳しくみていきます。(AWSの構成やデータ構造は記事用に簡略化しています)
DynamoDB→S3へのエクスポート
記事用にDynamoDBテーブルを作成しました。パーティションキーにはemailを設定しています。
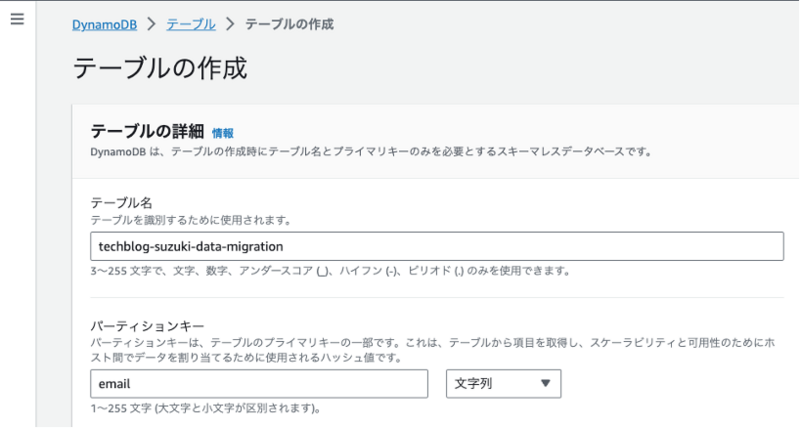
項目は、以下のとおりです。
| email (S) | account (L) | updated_at (N) | created_at (N) |
|---|---|---|---|
| test-user1@example.com | [{"name": "test-user1-1"}, {"name": "test-user1-2"}] | 1696129200 | 1696129200 |
| test-user2@example.com | [{"name": "test-user2-1"}] | 1696129200 | 1696129200 |
| test-user3@example.com | [{"name": "test-user3-1"}, {"name": "test-user3-2"}] | 1696129200 | 1696129200 |
このテーブルデータを開発環境に移動させるため、S3バケットにエクスポートします。
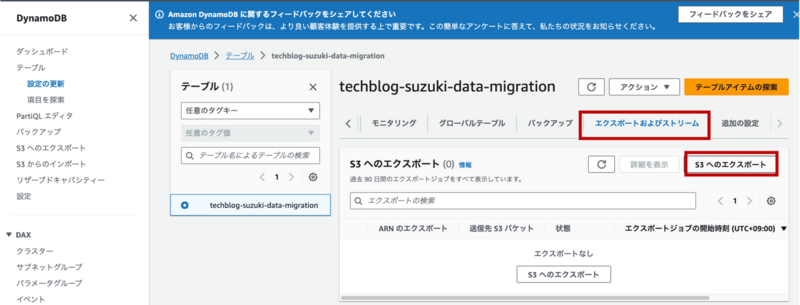
まず、エクスポート用にS3にバケットを作成します。
その後、DynamoDBのコンソール画面から、「エクスポートおよびストリーム」タブから「S3へのエクスポート」を選択することで、先ほど作成したS3バケットにデータをエクスポートします。
詳しい手順は、詳細はAWSの公式記事を参照してください。
開発環境へのダウンロード、変換処理
S3のコンソール画面から、先ほどエクスポートしたDynamoDBテーブル情報をダウンロードしてください。AWS CLIからaws s3 cp s3://[バケット名]/[データが配置されたフォルダパス] [ダウンロード先のフォルダパス] --recursiveでもダウンロード可能です。
ダウンロード後のデータは解凍しておいてください。DynamoDBのデータ量が多い場合は複数ファイルに分かれていることもあります。
gunzip ./input/fsjiydg6by6o5cjalruephgpca.json.gz -k
解凍後のデータを開くと、DynamoDBから出力したデータは以下のような形式となっています。DynamoDB JSON形式と呼ばれるらしいです。
// fsjiydg6by6o5cjalruephgpca.json {"Item":{"email":{"S":"test-user1@example.com"},"updated_at":{"N":"1696129200"},"account":{"L":[{"M":{"name":{"S":"test-user1-1"}}},{"M":{"name":{"S":"test-user1-2"}}}]},"created_at":{"N":"1696129200"}}} {"Item":{"email":{"S":"test-user2@example.com"},"updated_at":{"N":"1696129200"},"account":{"L":[{"M":{"name":{"S":"test-user2-1"}}}]},"created_at":{"N":"1696129200"}}} {"Item":{"email":{"S":"test-user3@example.com"},"updated_at":{"N":"1696129200"},"account":{"L":[{"M":{"name":{"S":"test-user3-1"}}},{"M":{"name":{"S":"test-user3-2"}}}]},"created_at":{"N":"1696129200"}}}
データベース(PostgreSQL)にデータをインポートするため、CSV形式に変換します。変換の過程で、DynamoDB JSON形式を扱いやすいJSON形式に変換するため@aws-sdk/util-dynamodbというパッケージを用います。
変換に用いた自作のスクリプトを一例として掲載します。
下記のコードをターミナル上で実行し、データをCSV形式で出力します。
./node_modules/.bin/ts-node convert.ts ./input
※「./input」はDynamoDBテーブル情報があるフォルダ
// convert.ts import * as fs from "fs"; import * as readline from "readline"; import { unmarshall } from "@aws-sdk/util-dynamodb"; import { Parser } from "json2csv"; // 型を定義 type Account = { name: string; } type UserTableFormat = { email: string; createdAt: Date; updatedAt: Date; }; type AccountTableFormat = { name: string; createdAt: Date; updateAt: Date; email: string; }; // 出力先のcsvファイルのヘッダーと値を紐づける const userTableFields = [ { label: "email", value: "email" }, { label: "createdAt", value: "createdAt" }, { label: "updatedAt", value: "updatedAt" }, ]; const accountTableFields = [ { label: "name", value: "name" }, { label: "createdAt", value: "createdAt" }, { label: "updatedAt", value: "updatedAt" }, { label: "email", value: "email" }, ]; // 各フォルダ・ファイルを定義 const inputFolder = process.argv[2]; const outputFilePath = "./output"; const outputUserTable = outputFilePath + "/userTable.csv"; const outputAccountTable = outputFilePath + "/accountTable.csv"; // 出力先のディレクトリを作成 fs.mkdirSync(outputFilePath, { recursive: true }); // 出力ファイルの初期化 fs.writeFileSync(outputUserTable, ""); fs.writeFileSync(outputAccountTable, ""); // DynamoDBテーブル情報ファイルの一覧を取得 const fileList = fs.readdirSync(inputFolder).filter((f) => f.endsWith(".json")); // 変換・書き込み処理 for (const inputFile of fileList) { const rs = fs.createReadStream(inputFolder + "/" + inputFile); const rl = readline.createInterface({ input: rs }); rl.on("line", (line) => { // 変換前に余分な文字列を削除 const inputLine = line .slice(0, -1) .replace(/{"Item":/, "") .replace(/\r?\n/g, ""); // DynamoDB JSON→JSONに変換 const inputData = unmarshall(JSON.parse(inputLine)); // テーブルごとにデータを分割 const userTableRecord: UserTableFormat = { email: inputData.email, createdAt: new Date(inputData.created_at * 1000), updatedAt: new Date(inputData.updated_at * 1000), }; let accountTableRecords: AccountTableFormat[] | null; if (!inputData.account) { accountTableRecords = null; } else { accountTableRecords = inputData.account.map((a: Account) => { return { name: a.name, createdAt: new Date(inputData.created_at * 1000), updatedAt: new Date(inputData.updated_at * 1000), email: inputData.email, } }) } // csv形式にパース const userTableParser = new Parser({ fields: userTableFields, header: false, withBOM: true }); const userTableCsv = userTableParser.parse(userTableRecord); let accountTableCsv if (accountTableRecords && accountTableRecords.length > 0) { const githubAccountTableParser = new Parser({ fields: accountTableFields, header: false, withBOM: true }); accountTableCsv = githubAccountTableParser.parse(accountTableRecords); } // テーブルごとにファイル出力 fs.writeFileSync(outputUserTable, userTableCsv.slice(1) + "\n", { flag: "a" }); if (accountTableCsv) { fs.writeFileSync(outputAccountTable, accountTableCsv.slice(1) + "\n", { flag: "a" }); } }); }
以上で、データの変換は完了し、outputフォルダに変換後のデータがテーブル単位でファイルとして出力されています。
S3バケットのルートに「upload」フォルダを作って、これらのファイルをアップロードします。S3のコンソール画面からでも、次のAWS CLIから(以下コマンド)でもアップロード可能です。
aws s3 cp ./output/ s3://[バケット名]/upload/ --recursive
RDSへのインポート
RDSに対して、psqlコマンドラインを使用してS3にアップロードしたcsvファイルデータを反映させていきます。
詳細は省きますが、RDSをプライベートサブネット内に作成している場合、踏み台サーバを使用するなどでデータベースにアクセスしてください。今回は踏み台サーバでポートフォワーディングを行い、RDSの対象データベースへ通信できる状態で、以下のコマンドを実行してデータベースに接続します。
パスワードの入力が求められるため、データベースユーザーに対応するパスワードを入力してください。
psql --host=localhost --port=5432 --username=[RDSのユーザー名] --dbname=[RDSのデータベース名] --password postgres
次に、psqlを用いてS3のファイルデータをRDSにインポートするため、以下のコマンドからaws_s3拡張機能をインストールします。
CREATE EXTENSION aws_s3 CASCADE;
\dx コマンドを実行し、aws_s3 拡張機能がインストールされていることを確認します。
postgres=> \dx
List of installed extensions
Name | Version | Schema | Description
-------------+---------+------------+---------------------------------------------
aws_commons | 1.2 | public | Common data types across AWS services
aws_s3 | 1.1 | public | AWS S3 extension for importing data from S3
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(3 rows)
ここが今回の本題です。
課題にも記載しましたが、userテーブルのidはレコードが作成されるまで生成されないため、accountテーブルの外部キーであるuser_idはCSV形式に変換するタイミングでは確定させることができませんでした。
今回は以下の方法で解決しました。
- userテーブルのユニークカラム(email)をフィールドに持つ account_tmpテーブルを作成する。
- S3にアップロードしたcsvファイルを、userテーブルとaccount_tmpテーブルに取り込む。
- userテーブルに作成されたレコードからaccount_tmpテーブルに設定したユニークフィールドをもとにidを取得し、account_tmpテーブルのuser_idを更新する。
- account_tmpテーブルのレコードをaccountテーブルにINSERTする。
- account_tmpテーブルを削除する。
具体的には以下のSQLファイルをpsqlから実行します。
\i data_migration.sql
-- data_migration.sql -- 1. account_tmpテーブルを作成する CREATE TABLE "account_tmp" ( "id" SERIAL NOT NULL, "name" TEXT NOT NULL, "user_id" INTEGER, "created_at" TIMESTAMP(0) NOT NULL DEFAULT CURRENT_TIMESTAMP, "updated_at" TIMESTAMP(0) NOT NULL DEFAULT CURRENT_TIMESTAMP, "email" TEXT NOT NULL, CONSTRAINT "account_tmp_pkey" PRIMARY KEY ("id") ); -- 2. S3にアップロードしたcsvファイルを、userテーブルとaccount_tmpテーブルに取り込む SELECT aws_s3.table_import_from_s3( '"account_tmp"', -- テーブル名 '"name", "user_id", "created_at", "updated_at", "email"', -- カラム名 '(format csv)', -- ファイル形式 'bucket-name', -- バケット名 'upload/accountTable.csv', -- バケットルートからのファイルパス 'ap-northeast-1' -- リージョン ); SELECT aws_s3.table_import_from_s3( '"user"', '"email", "created_at", "updated_at"', '(format csv)', 'bucket-name', 'upload/userTable.csv', 'ap-northeast-1' ); -- 3. ユニークフィールドをもとにidを取得し、account_tmpテーブルのuser_idを更新する UPDATE "account_tmp" SET "userId" = "user"."id" FROM "user" WHERE "account_tmp"."email" = "user"."email"; -- 4. account_tmpテーブルのレコードをaccountテーブルにINSERTする INSERT INTO "account" ("name", "user_id", "created_at", "updated_at") SELECT "name", "user_id", "created_at", "updated_at" FROM "account_tmp"; -- 5. account_tmpテーブルを削除する DROP TABLE "account_tmp";
以上で無事にRDSへデータを移行できました。
ちなみに開発環境のデータベースに取り込む際は、以下2点を変更してください。
- psqlでデータベースにログインする際、開発環境のデータベースホスト名・ポート番号・データベース名・ユーザー名に置き換えて実行する。
- 「data_migration.sql」の「2. S3にアップロードしたcsvファイルを、userテーブルとaccount_tmpテーブルに取り込む」部分を開発環境のcsvファイルからデータを取り込むように修正して、
\i data_migration.sqlを実行する。
-- data_migration.sql -- (省略) -- 2. csvファイルをテーブルに取り込む \COPY "account_tmp" ("name", "user_id", "created_at", "updated_at", "email") FROM './output/accountTable.csv' DELIMITER ',' CSV \COPY "user" ("email", "created_at", "updated_at") FROM './output/userTable.csv' DELIMITER ',' CSV -- 3. ユニークフィールドをもとにidを取得し、account_tmpテーブルのuser_idを更新する -- (省略)
まとめ
今回は、DynamoDBからRDSへデータを移行する際に苦戦したことを記事に残しました。user_id問題以外にも、DynamoDB JSONの変換方法など色々と勉強になりました。
同じ場面に出くわす機会は少ないと思いますが、どなたかの参考になれば幸いです。
最後までお読みいただきましてありがとうございました。
私たちは一緒に働いてくれる仲間を募集しています!
フルサイクルエンジニア執筆:@suzuki.takuma、レビュー:@yamashita.tsuyoshi
(Shodoで執筆されました)



