
お疲れさまです。XI本部、AIトランスフォーメーションセンターの徳原 光です。
この記事で2回目の投稿になります。今回は所属センターで開発しているAI製品、TexAIntelligenceを使用して、SNSでの投稿に感情ラベルを付与したデータセットであるWRIMEデータセットver.2をAIモデルに学習させた結果をまとめたいと思います。
感情分析とは?
感情分析はNLP、自然言語処理の一手法で文章に込められた感情をAIによって検出する技術です。
例えば、「お風呂の水漏れが治らない・・・。今月でもう3度目だよ」という文章には「悲しみ」が込められていますよね(もしかしたら「怒り」もあるかも)。
「〇〇大学に合格できた!春からはれて大学生だ!!」という文章だったら「喜び」でしょうか?
もし、「〇〇大学に合格できた!春からはれて大学生だ!!嬉しいなぁ」というように「嬉しい」とか、「やったー」という言葉が含まれていれば、ルールベースによる手法や従来の機械学習の手法で文章が意味する感情を判別することが可能です。
しかし、そのような感情を表す言葉が含まれていない場合、文章の文脈を理解する必要があるので、感情分析はNLPのタスクの中でも難しい課題と言えます。
WRIME 主観と客観の感情分析データセット
こちらのデータセットは愛媛大学の梶尾先生が作成されたデータセットです。
BERTの学習用のデータセットとして作成されたので、機械学習で使用するデータセットとしては非常に使い勝手がいいデータセットになります。
ver1では43,200件、ver2では35,000件のSNSから収集した文章データに基本8感情(喜び、悲しみ、期待、驚き、怒り、恐れ、嫌悪、信頼)の感情極性が書き手と3人の読み手ごとに4段階(0:無、1:弱、2:中、3:強)でラベル付けされています。
さらに、ver2では肯定的か否定的かのラベルも5段階で付いていて、今回はそれを利用しました。
NLPの世界では、いつの世でも学習データが不足してしまうものですが、数万件の文章データがあるのでデータ数で困ることはありません。しかも、一つの文章に複数のラベルが付けられているので、アイデアしだいでいろいろな応用ができます。
また、ver1では80人、ver2では60人の書き手から文章を収集しているのでいろいろな文体の文章が収録されており、さらにSNSの特性上、内容のジャンルは様々なので非常に汎用性の高いデータセットになっています。
TexAIntelligence
TexAIntelligenceは、私が所属しているAIトランスフォーメーションセンターで開発している、文章分析のためのアプリケーションになります。
AIに知見がない人でも高度なAI技術を使いこなせるというコンセプトのもと開発を進めていて、webの画面をポチポチ操作するだけで、AIモデルを構築し利用できます。
使用できるアルゴリズムはTF-IDFと日本語の文章認識に特化したBERTモデルであるISID-BERTの2つです。
ISID-BERTを利用する場合、予め学習により日本語の認識精度を高めた状態のモデルをユーザーが用意したデータセットで転移学習(ファインチューニング)させ、目的のタスクを実行するAIモデルを構築することになります。
今回の場合では、WRIMEデータセットを予めアップロードしておき、データセットに含まれる感情に関するラベルをISID-BERTに学習させることで、TexAIntelligence上で感情分析を実施していきます。
感情分析をやってみる
新人研修の一環として今年度の新入社員向けに、NLPと社内製品であるTexAIntelligenceを紹介することになり、ISID-BERTを使うメリットがわかりやすく説明できる題材を探していました。
あまりにも簡単だと、高度な深層学習を行うISID-BERTを利用する意味が伝わらないので、単語レベルではなく文脈を理解しないと正解できないタスクに挑戦する必要があり、感情分析がベストだと思いました。
さらに、新入社員の人も自分でTexAIntelligenceを使いたくなるような汎用的なユースケースにしたかったので、 文章が肯定的なものか、否定的なものか、中立的なものか判断するタスクを実施します。
セミナーやイベントで集めたアンケート回答の自由記述欄が肯定的な意見なのか、否定的な意見なのか分類したいというニーズは社内でもありますし、お客様向けに開発しているシステムにも取り入れやすい機能だと思います。
## データ準備 WRIMEデータセットには肯定的か否定的かのラベルが5段階(肯定強、肯定弱、中立、否定弱、否定強)でついていますが、そのまま5段階での分析をAIモデルにさせると、かなり肯定的な文章とちょっと肯定的な文章の区別をAIにさせることになり、タスクの難易度が上がってしまいます。
人がこれらのタスクをやる場合でも、肯定しているのか、否定しているのかの判断は容易にできますが、どのくらい肯定しているのか、否定しているのか判断は難しいですよね・・・。WRIMEデータセット上でも3人の読みての判断が一致していないことが多々あります。
なので、タスクをよりシンプルにするように、肯定強、肯定弱は同じ肯定的に、否定弱、否定強は同じ否定的にまとめて、肯定、中立、否定の3段階にラベルを作成しておきました。
また、WRIMEデータセットには書き手と読み手の合わせて4人分の文章の評価が記録されていましたが、読み手の3人の評価を平均したものをISID-BERTに予測させるラベルとしました。
学習データのアップロード
ここからはTexAIntelligenceの画面上で操作を行います。
 学習データ数は10,000件で実施しました(実際はそのうち2割が評価用になるので8000件が学習データになります)。データセットにはそれ以上のデータが収録されていますが、学習時間の都合上1万件としました。
学習データ数は10,000件で実施しました(実際はそのうち2割が評価用になるので8000件が学習データになります)。データセットにはそれ以上のデータが収録されていますが、学習時間の都合上1万件としました。
学習実施
GUIの画面上の操作について軽く説明します。ただし、この記事は製品紹介ではありませんので詳細な操作方法については割愛しています。
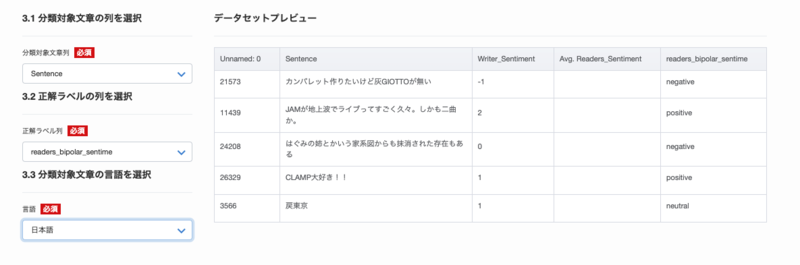
学習の設定としてやることは、文章に対応する行と、AIに判定させたい感情を表すラベルを指定するだけです。細かい学習パラメータを設定することも可能ですが、今回は特にこちらからパラメータを指定しませんでした。
BERTの学習が走るVMによってかかる時間は変わりますが、この時利用した環境(K80搭載)では10,000件の学習を約2時間で完了しました。
もうちょいマシなGPU(例えばT4やV100、RTX3080 tiやRTX 3090)を積んだ環境を利用すればもっと早く学習が終わると思います。
学習結果
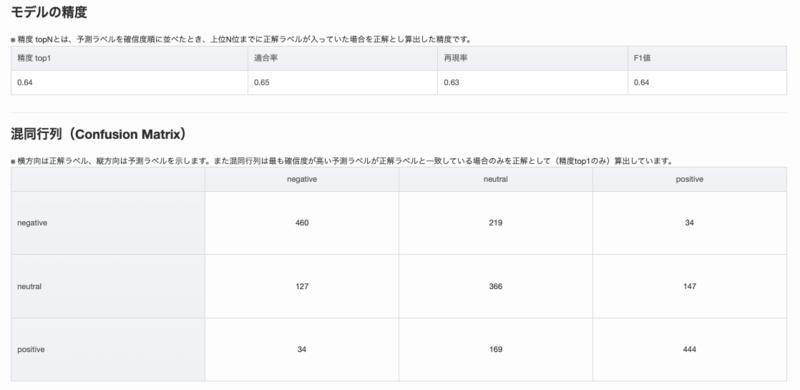
64%正解という微妙な結果になってしまいましたが、今回は肯定的、中立的、否定的と3段階のラベル付けを行っており、肯定的を否定的に、もしくは否定的を肯定的に間違えた件数は2000件中、68件だったのでそれほど多くありませんでした。
学習データを工夫すればもうちょっと精度をあげられるかもしれませんね。
例えば、学習データに含まれる肯定的、中立的、否定的の割合を調整するとか、評価者によって判断が分かれているデータを除外するなど、やりようはいくらでもあると思いますが、今回はあくまでお試しなのでこれで良しとします。
また、アンケート分析というユースケースでの利用を検証するために、自分で一文一文作成したアンケート回答の自由記述のサンプルデータを使ってモデルをテストしてみました。
結果は83%正解。まずまずの結果だと思います。アンケートのサンプルデータは30回答分しかないので明らかにデータ数が足りませんが、試した結果だけ見ると自由記述のサンプルデータの方が精度が高いようですね。
理由は単純にアンケートの自由回答よりも、WRIMEデータセットのSNSの投稿文のほうが、感情を分析するのが難しいからでしょうか。
SNSの文章は前後の投稿の関係性や投稿された時節、投稿者の気分によって言葉のニュアンスが変化してしまいます。
ちなみに、書き手ではなく読み手の評価をラベルとして採用したのもこれが理由で、投稿者の評価をラベルにしてしまうと完全に同じ文章なのにラベルが違うってことが増えてしまうんですよね。
ここら辺の話は梶原先生のこちらの論文で考察されているので気になる方は読んでみてください。
アンケートの自由記述は他人に読まれることを前提に書かれた文章なので、その文章単体で読み手が意味を理解できるように必要な情報は全て盛り込まれているはずです(そうじゃないこともありますが・・・)。なので、AIが文章のみから肯定的か否定的かを判断するのは比較的に簡単だったんだと思います。
以下はアンケートのサンプルデータの文章と正解ラベル、予測ラベルの一部になります。
| 文章 | 正解ラベル | AIが予測したラベル |
|---|---|---|
| UIが素晴らしいと思う。直感的に操作できるので操作方法を調べなくても利用できる | positive | positive |
| 直近で大量のアンケートを集計する必要があり、このソフトを用いたことろ効率的にアンケート集計ができた。便利だったので今後も利用したい。 | positive | positive |
| 日本語の認識精度が高くて驚いた | positive | negative |
| 最高! | positive | positive |
| ぜひ継続して利用したい | positive | positive |
| 他の製品と違いはないと感じた | neutral | neutral |
| 価格は普通だと感じた。 | neutral | neutral |
| 月に3回ほど利用した。費用頻度はそれほどでもないと思う。 | neutral | neutral |
| AIについて今後勉強したいと思う | neutral | positive |
| ノーコメント | neutral | neutral |
| 競合のA社も利用しているのでしょうか | neutral | neutral |
| 利用していない | neutral | negative |
| 特になし | neutral | neutral |
| 利用方法が理解できなかった。もっとマニュアルを整理しないと活用できないと思う | negative | negative |
| 精度が低い、使いものにならない | negative | negative |
| 機能に対して利用料金が高すぎると思う。また、クラウドに文章データを送るのでセキュリティも不安に思っている | negative | negative |
| 導入する意味はない | negative | neutral |
| UIがわかりにくい。使っているとイライラする。 | negative | negative |
ちょっと考察
唯一、肯定的を否定的と間違えたのは下の文章でした(否定を肯定に間違えることはありませんでした)。
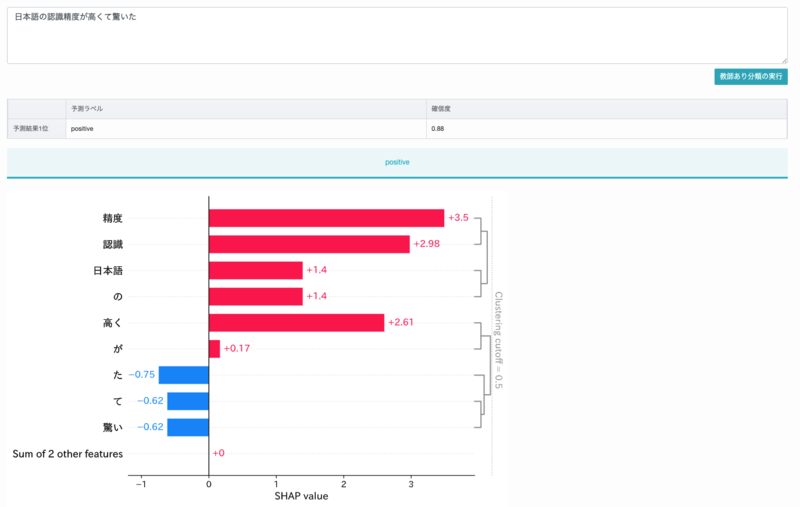
日本語の認識精度が高くて驚いた
この文章は肯定的な文章ですが、認識精度が高いことが良いことなのか悪いことなのか判断できないと、文章全体が肯定なのか、否定なのか判断できないですよね。ちなみに、学習データの中には「認識精度」という言葉は含まれてなく、「精度」という言葉も2回しか出てきません。

上の図はTexAIntelligenceに搭載されているSHAP(AIの判断根拠を可視化する技術)によって単語別の否定の判断の寄与度を表したものです。「高くて驚いた」の部分が否定の判断根拠になっています。例えば価格が高い場合この文章は否定的なものになりますよね。
肯定的と中立的、もしくは中立的と否定的の区別で他にも間違えはありましたが、共通して言えることは文章が短いと間違いやすいということです
SNSの文章は短いと書き手のメタな情報を理解していないと意味がわかりづらくなるので、AIがその文章だけで正解のラベルを判断するのは難しいのだと思います。
逆に長い文章ならば、主張の背景的な情報も投稿に含まれるようになるため、AIが文章から感情を推測することも可能になります。
例えば、「ヤバかった!」と一言だけの文章では、ポジティブなヤバいなのか、ネガティブなヤバいなのかわかりませんが、もしこの投稿に文章をたして、
「一昨日ライブで披露された新曲がマジでヤバかった!」
となっていれば、AIはライブでの出来事だったことや、新曲に対する意見ということでヤバいが肯定的な評価だと推測できるわけです。
ただ、これはSNSに限った話で、一般的にビジネス文章に関しては文章が短いと精度が上がると言われていいます。
それは、ビジネス文章は読み手に正しく伝えたいことを理解してもらうことが目的に書かれるため、メタな情報も含め判断の根拠となる情報は全て文中で述べられることが多く、推測に必要な情報が不足しにくいからです。
逆に、文章が長いと主張とは関係ない補足情報が増えていくため、文に含まれる単語数が増えるほどAIは文脈の流れを見誤る可能性が増えます。サンプルのアンケート文章はどちらの特性が強いかというと、ビジネス文章に近いと言えます。
個人的にはアンケートの回答と趣が違うSNSの文章を学習して、ここまで精度が出たのが驚きですが、SNSの文章のほうがより多くのジャンルや概念を含んでおり汎用的だったということだと思います。
すこし実験
日本語の認識精度が高くて驚いた
先程、これを間違えて否定的と捉えたのは「〇〇が高い」だけでは肯定か否定か判断できず、「認識精度が高い」 という組み合わせが学習データになかったので正しい判断ができなかったと書きました。
それなら、同じような文章を学習データに仕込んでおけば正解できるはずです。そして、TexAIntelligenceに搭載しているISID-BERTは日本語のコーパスを学習させているので、完全に同じ言葉ではなくても似た意味を持つ単語が含まれていれば文脈の意味を理解できます。
ということで、文章:「予測の正確性が高水準になっている」ラベル:肯定的というデータを学習データに追加しました。
これで、間違えてしまった「日本語の認識精度が高くて驚いた」も正しく文意を捉えられるはずです。
結果は・・・
素晴らしいですね。スッキリしました。これで今日もよく眠れそうです。
まとめ
WRIMEデータセットはめっちゃイカしたデータセットでした。
今回はサクッと使わせていただきましたが、それだけでも十分な結果が得られました。
豊富なデータ数と複数のラベルが存在しているので他にもいろんな応用の仕方ができると思います。
研究目的で作成されたデータセットということでビジネス利用は難しいかもしれませんが、NLP技術の研究にはかなり有効なデータセットですね。
これだけのデータセットを作成するのはとても大変だったかと思います。構築に関わった方々に感謝です。
それでは。
執筆:@tokuhara.hikaru、レビュー:@sato.taichi (Shodoで執筆されました)



