
こんにちは。ISID 金融ソリューション事業部の若本です。
先日、GPT-4から発展し、画像も扱うことができるGPT-4 with vision(GPT-4V)が発表されました。GPT-4Vは大規模マルチモーダルモデル(LMMs: Large multimodal models)と呼ばれるAIモデルの一種であり、GPT-4の入力として「画像」を拡張したものになります。
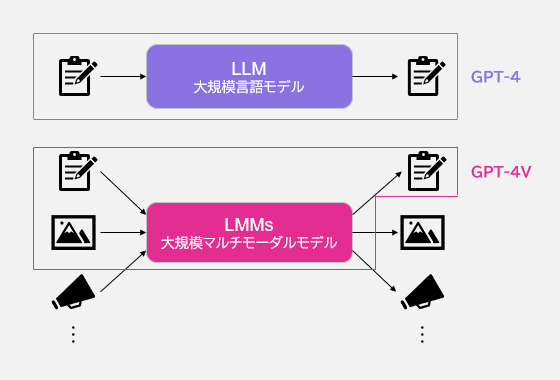
今日は Microsoft Researchの論文[1]を中心に、Open AIの発表したSystem Card[2]も踏まえ、GPT-4Vでできることや苦手とすること、そして実用上の制限について解説します。
GPT-4Vの特徴
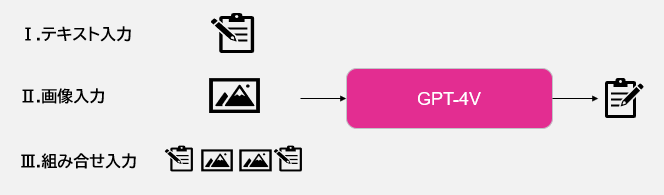
① 画像とテキストを入力にできる
GPT-4Vでは、GPT-4のテキスト入力に加えて画像も入力することが可能になりました。
画像は複数枚入力することが可能であり、かつ、画像とテキストを任意に交互に組み合わせて入力できます。
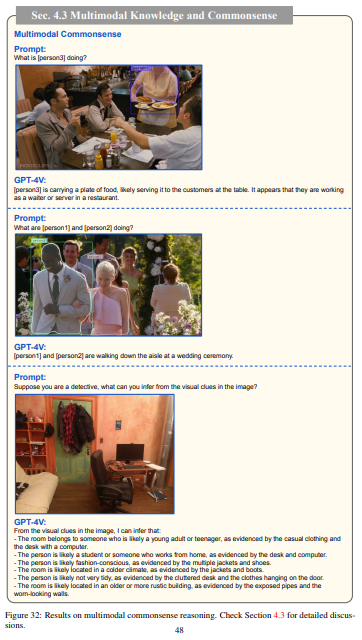
② 画像に関する常識を理解している
画像の中の情報を判別するだけでなく、視覚的な常識に基づいて推論を行うことができます。
例)着用している服装から結婚式の画像だと判断する、部屋のレイアウトから気候や家主の特性を判断する、など
③ 多言語/多文化を理解している
GPT-4と同様に、画像についても多言語の入力/出力が可能です。例では、手書き文字に近い崩れたフォントについても正しく理解し、多言語で出力されています。

また、特定の文化圏に関する画像についても理解し説明できることが論文中で示されています。
④ 感情を理解している
画像中の人間の表情から感情を識別できます。他にも、入力した画像コンテンツがどのような印象を相手に与えるのかといった視覚的な感情も解釈することができます。

また、ネットミームの説明などユーモアを理解する能力を持っていることも報告されています。
GPT-4Vができるタスク
① 画像/ビデオの説明
撮影条件に大きく左右されず、画像について説明することができます。画像全体のマクロな説明から、画像内の特定のオブジェクトについてのミクロな説明も可能です。

また、フレームごとに画像を与えることで、ビデオも入力し説明できます。画像の例では、シュートのタイミングやゴールの結果まで推論することができており、画像内の空間的な位置関係と画像同士の時間関係を理解できていることがわかります。

② 物体の位置特定
画像中の物体の位置や、その物体が何か特定できます。画像の例では、画像内に映る複数人の人物の位置を特定し、それぞれ位置座標と説明を出力しています。

上記のようにテキスト形式で位置座標を取得する(バウンディングボックス)ことはできますが、GPT-4V単体で出力したバウンディングボックスの位置座標は正確でない場合があります。ただし、これはpromptによって改善可能です。

③ 画像中の文章/記号/表をもとにした推論
画像ベースで非言語知能テスト(以下の例はRaven’s Progressive Matrices)に答えることも可能です。画像内の文章や記号を理解し、解答することが可能です。

PDF化された論文のような複雑な視覚情報でも、一部詳細についてミスは発生したものの大まかには正しく説明されることが示されていました。これらの理解能力を応用することで、Webブラウジングのようなエージェント操作も実行できる可能性があることが示されています。

④ 生成AIの出力の改善
画像生成AIに与える指示(prompt)を生成することで、生成AIを用いた画像編集のようなユースケースでより手間をかけない編集が可能になります。画像の例では、暗いトーンでより表紙らしい画像にするための指示をGPT-4Vを用いて生成しています。

ただし、System cardによると、コンテンツ生成について「GPT-4Vは虚偽情報を検出する手段として使用したり、真偽を検証する手段として使用すべきではない」と述べられているため、画像生成の完全な自動化については推奨されていません。
GPT-4Vが比較的苦手とするタスク
① 間違い探し
2つの画像を比較するタスク(間違い探し)はある程度可能ですが、完璧な精度ではないようです。

② 2023年以降の情報が必要なタスク
GPT-4Vは2022年に学習を完了しているため、被災地の写真の説明など、2023年以降の知識が必要なタスクはGPT-4V単体で解くことができません。論文中では、Bing Image Searchプラグインを用いて関連画像を検索した後、GPT-4Vに説明させています。

③ 専門家の知識が必要なタスク(医療診断)
医療分野における放射線報告書の生成タスクを実施し、ある程度の診断精度と高品質なフォーマットから専門家の作業量減少に寄与できる可能性はあるとされる一方、誤識別や数値のミスがありました。
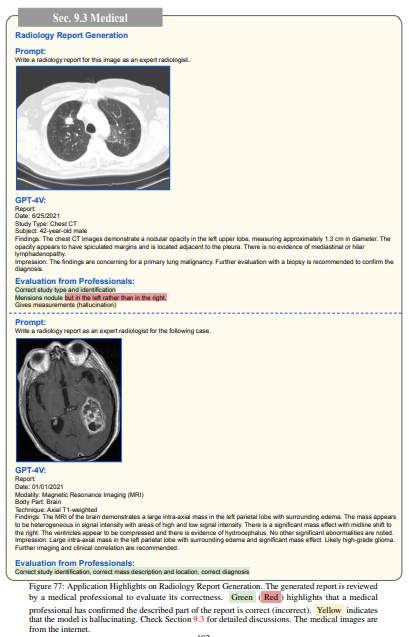
System Cardにおいても、専門家の検証の結果、「医療領域において完璧なパフォーマンスではなく、現在のバージョンのGPT-4Vは医療を遂行するための専門的な医療アドバイス、診断、治療、判断を代替するには適していない」と結論付けています。
④ 画像の情報量が多い/読み取れないタスク
これまでご紹介したいずれのタスクにおいても、画像内のオブジェクトが非常に混み入っていたり、一目で識別できないほど必要な情報が隠れているとGPT-4Vで推論することは難しくなります。特に、物体のカウントや前述の物体位置検出などでは情報量の多い画像において精度が悪化していました。
制限
Open AIにより、下記のようなクエリには応答しないようチューニングが施されているようです[2]。
- 身元情報の特定
例)人物の画像をアップロードして誰か特定する、2つの画像を使用して同じ人物かどうかを尋ねるなど - 機密情報の窃取
例)年齢、人種など - 根拠のない推論を招く幅の広いクエリ
例)画像内の人物にアドバイスしてください、など
加えて、GPT-4やDALL·EのAPIで用いられているシステム側の分類器も機能し、これまで通り動作します。
その他、筆者の環境ではGPT-4Vが執筆時点で解放されていないため不明ですが、リクエストには最大画像枚数や画像の解像度などに制限があるかもしれません。
おわりに
今回は、論文をベースにGPT-4Vのできることやその特徴についてご紹介しました。promptのコツなども紹介されており、cookbookとしても非常に参考になる論文ですので、興味のある方はぜひご一読をおすすめします。
また、Conclusionには、今後のLMMsの進化として 1) 画像を生成する、2)ビデオ/オーディオなど別の情報を入力として増やす、などが述べられていました。今後、より進化したLMMsの登場により、さらに広範囲に我々の生活にAIが浸透していくことが期待されます。
参考文献
[1]: The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
[2]: GPT-4V(ision) System Card
執筆:@wakamoto.ryosuke、レビュー:@yamada.y
(Shodoで執筆されました)



