
こんにちは、X(クロス)イノベーション本部 クラウドイノベーションセンターの田村です。
2023 年 5 月の Microsoft Build にて統合分析プラットフォーム Microsoft Fabric が発表されました。
Microsoft Fabric は現在プレビュー中ですが、既存のサービスにはない機能追加や多くのアップデートが予定されており、Microsoft のデータ領域ビジネスにおいて今後注目すべきサービスです。
本記事では、Microsoft Fabric の概要とサービス検証として実施した勤怠データ分析の内容をご紹介します。
Microsoft Fabric の概要
Microsoft Fabric は、データ分析に必要な要素を 1 つの統合環境で提供する SaaS 形式のソリューションです。
従来 Microsoft のクラウドサービスでデータ分析をする場合は、Azure Data Factory や Azure Synapse Analytics といった PaaS を組み合わせたアーキテクチャを設計する手法が一般的でした。
Microsoft Fabric では、データの蓄積/加工/変換/分析/可視化を単一の基盤上で実現できるため、ユーザーは統一された UI 上でシームレスな分析を実施できると謳われています。
これにより、ユーザーは 1 つのサービス内でデータ分析やデータ管理に関する作業をすべて完結でき、分析リソースのサイジングといった管理負担の軽減が期待できます。
Microsoft Fabric の主要な構成要素について述べます。
記事のボリュームを考慮し、今回は技術検証にて扱った要素について簡潔に説明しますので、他にも興味がある方はこちらのリンクをご参照ください。
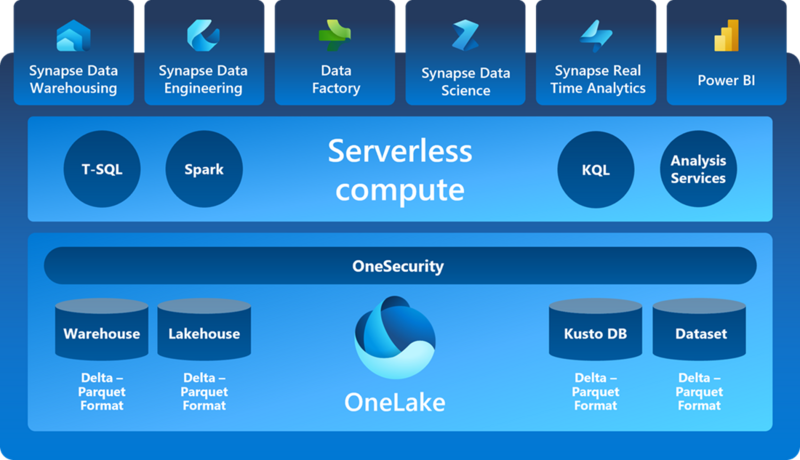
One Lake
Microsoft Fabric の環境に 1 つ作成される SaaS 形式のデータレイクです。
Microsoft Fabric の各機能で利用されるデータを一元的に管理する基盤であり、ショートカットと呼ばれる機能を利用するとさまざまなサービスから手軽にデータを移動できます。
現時点では Microsoft Fabric 内部/Amazon S3/Azure Data Lake Storage との連携が実装されており、今後も拡大されていくと思われます。
Synapse Data Engineering
レイクハウスと呼ばれる構造化/非構造化データを管理・分析できるデータストアに格納されたデータに対する処理を行う機能です。
具体的には Apache Spark クラスタによる分析やノートブックによる対話的な分析(Python/R/Scala)、データパイプラインによるデータの移動/変換/結合等が実施できます。
Data Factory
既存のデータ統合サービスである Azure Data Factory と、Excel や Power BI 等に搭載されている Power Query を組み合わせたデータ統合機能です。
さまざまなデータソースからデータを取り込み、柔軟な処理が可能です。
Power BI
Microsoft Power Platform にて提供されている BI ツールです。
Microsoft Fabric に可視化コンポーネントとして統合されています。
サービス検証:勤怠データの分析
概要
7 月上旬あたりで Microsoft Fabric のキャッチアップとチュートリアルの実施がある程度進んだので、手持ちのデータを使用して Microsoft Fabric での分析に着手しました。
分析作業を通じて、下記の項目について検証することを目的とします。
- Microsoft Fabric のみでデータ分析を一気通貫で実施できるか
- データ分析の経験があまりないユーザーをサポートする機能が現時点でどの程度実装されているか
- Microsoft Fabric の操作感(Power BI や Data Factory など統合されたサービスがこれまで通り利用できるか)
検証シナリオ:勤怠データ分析
ISID では日々の勤怠入力を自社ソリューションである POSITIVE で実施しています。
ISID 社内で利用している POSITIVE では、入力した勤怠情報を Excel 形式でダウンロードできます。
そこで、自分の勤怠データが記録された Excel ファイルを Microsoft Fabric で分析し、可視化までの工程を一気通貫で検証してみることにしました。
検証アーキテクチャ
アーキテクチャと検証手順は下記の通りです。
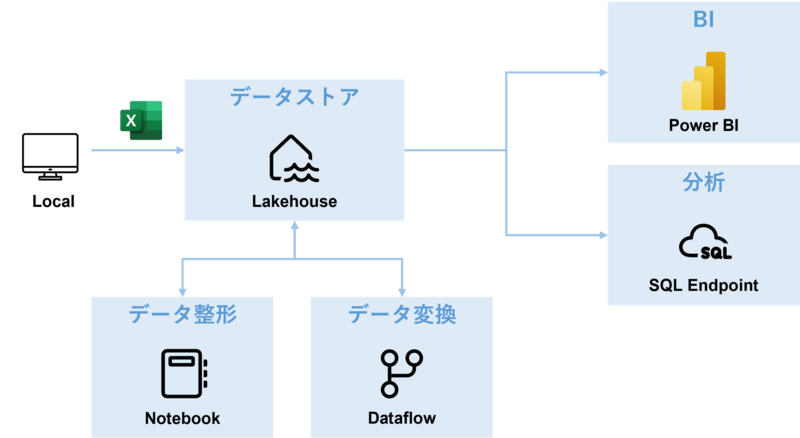
- Microsoft Fabric サブスクリプションを購入する
- Microsoft Fabric ワークスペースを作成する
- Synapse Data Engineering にてデータストアとなるレイクハウスを作成する
- ローカルから Excel 形式の勤怠データをレイクハウスへ格納する
- ノートブック を作成し、Excel 形式の勤怠データを整形して再度レイクハウスへ格納する
- 整形された勤怠データをデータフローにて変換・加工し、再度レイクハウスへ格納する
- レイクハウスから SQL エンドポイントを作成し分析を実施する
- 変換後のデータおよび分析結果を Power BI にて可視化する
Microsoft Fabric サブスクリプションの購入
Microsoft 365 もしくは Azure 上から購入できます。
今回は Azure 上から購入しました。
手順は簡単かつドキュメントの内容をなぞるだけですので、本記事では割愛します。
Microsoft Fabric ワークスペースの作成
ワークスペースとは、Microsoft Fabric で作成したさまざまなコレクション(レイクハウス、データフロー、BI レポート etc...)をまとめて管理するものです。
Microsoft Fabric で作業を開始する際には、内容を問わずはじめに実施する工程となります。
手順としてはワークスペース名を入力して保存するだけですので、こちらについても詳細は割愛します。
厳密にはワークスペースに対する権限設定などもありますが、今回は検証用ワークスペースのため実施していません。
レイクハウスの作成
レイクハウスは、大容量のデータを蓄積するデータレイクとデータの取り込みや分析に特化したデータウェアハウスを統合したものです。
一般的に構造化/半構造化/非構造化データを 1 箇所で管理・分析することが可能で、Microsoft Fabric では多様なデータソースからのデータ格納とデータに対するさまざまな変換・統合処理や SQL や Spark エンジンを利用した分析をサポートしています。
また Microsoft Fabric におけるレイクハウスの特徴として、格納されたデータを自動で検出し、分析に適した形式でテーブルとして登録する機能も用意されています。
作成自体は非常に簡単で、Microsoft Fabric ワークスペースの[+ 新規]より[レイクハウス]を選択し任意の名前を設定して完了です。
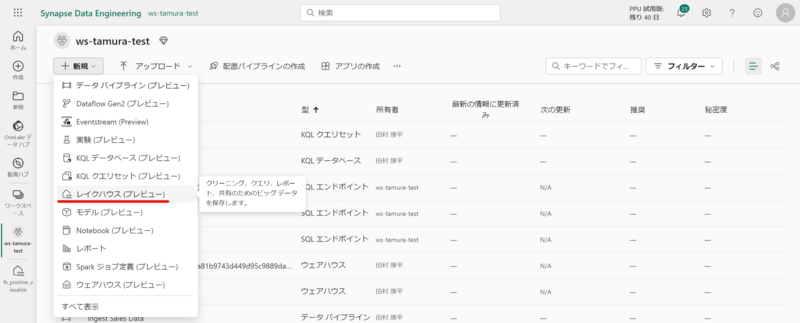
勤怠データの格納
検証に必要なデータを作成したレイクハウスへ格納します。
対象となるのは、私の 2023 年 6 月分の勤怠実績を記録した Excel データ(ファイル名:Attendance_202306.xlsx)です。
作成直後のレイクハウスには 構造化データが管理される Tables とデータレイクのようにさまざまなソースから連携された生データが管理される Files というセクションが用意されています。
データ格納をする際はデータフローやパイプラインを利用する方法や、One Lake のショートカット機能などさまざまな選択肢がありますが、今回はシンプルに手動でアップロードしました。
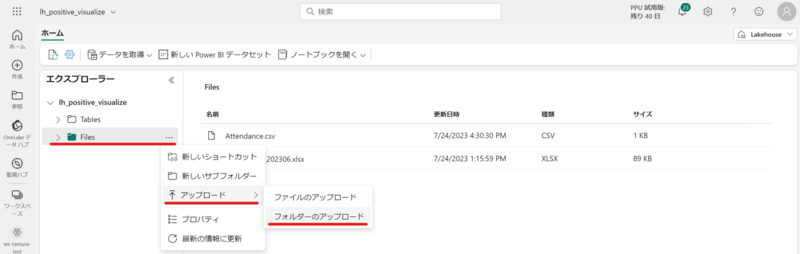
アップロードが完了するとデータ形式によってはプレビュー表示が可能ですが、2023 年 7 月時点で Excel データはサポート外のようです。
ノートブックによるデータの整形
生データの時点である程度構造化されていればよいのですが、検証で扱う勤怠データは分析用にフォーマットされたものではないため、 変換や統合処理の前にデータを整形する必要があります。
そこで、今回は Spark エンジンが接続されたノートブックによるデータの整形を実施しました。
ほかの選択肢としてデータフロー(Power Query)も検討しましたが、そちらはこの後の作業であるデータの変換・加工処理で利用しています。
ノートブックはレイクハウス UI の[ノートブックを開く]より作成できます。

ノートブックの作成と同時に Spark エンジンも用意されるため、ユーザーは言語を選択して処理を記述していくだけです。
私は Python を選択しましたが、その他に Scala/C#/R/Spark SQL がサポートされています。
データ整形の内容としては、Excel 形式の勤怠データをより必要なデータを抽出し、Python のデータフレームを利用してデータを再配置しています。
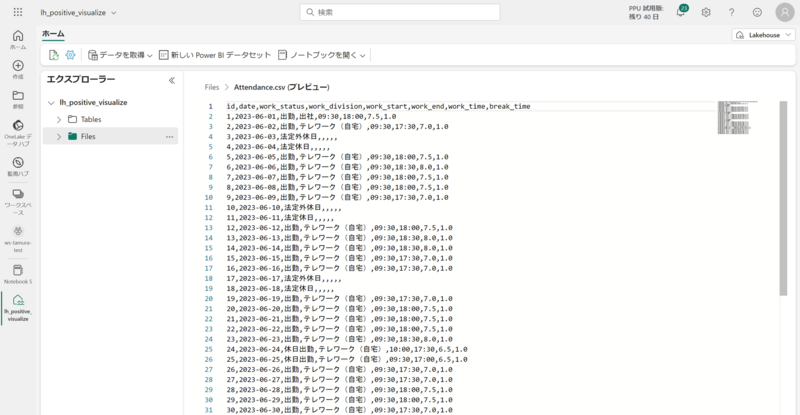
抽出したデータは下記の通りです。
- 日付
- 勤務区分(出勤/法定休日/有給など)
- 勤務形態(出社/テレワーク/顧客先など)
- 勤務開始時間
- 勤務終了時間
- 勤務時間
- 休憩時間
また、整形後のデータはレイクハウス内でプレビュー表示させたかったので、CSV 形式のファイルとして Files セクションに格納しています。
整形後のデータは下記の通りです(ファイル名:Attendance.csv)。
データフローによるデータの変換・加工
整形したデータに対して、変換・加工処理を実施し分析の準備を行います。
前述したノートブックでまとめて実施してもよかったのですが、他の機能も触ってみたいという思いでデータフローによる作業としました。
データフローは Microsoft Fabric の UI より Data Factory を選択し、[Dataflow Gen2(プレビュー)]より作成できます。
作成後はレイクハウスに格納されている整形後の勤怠データ(Attendance.csv)を読み込み、必要な処理を実施します。
今回実施した主な処理内容は下記の通りです。
- 勤務開始/終了時間のデータ型を文字列型へ変更する
- 定時を表現する列を追加する
- 勤務時間と定時を計算し、残業時間を表現する列を追加する
- 勤務区分に休日出勤が含まれる場合は、勤務時間を残業時間として追加する
実際のデータフロー画面は下画像のようになります。
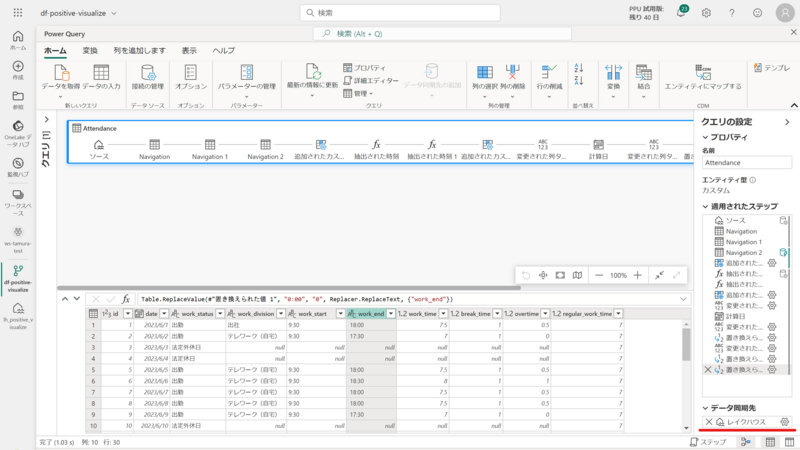
ノートブックと異なり、コード(Power Query)を記述できなくとも GUI 上の操作で基本的なデータの変換・加工が可能です。
もちろん、必要に応じて直接 Power Query を書くこともできます。
また、処理のサマリがダイアグラムビュー(画像内の青枠部分)に記録され処理結果は画像下部にプレビューされるので、処理に対する結果を即時把握できます。
データ変換が完了したら、画像右下の[データの同期先]よりレイクハウスへの同期設定を行うことで、分析用に最適化された形式で Tables セクションへ格納されます。
また、その際のスキーマ定義やデータ構造の作成などはすべて自動で実施されます。
データフローからレイクハウスへの同期が完了すると、Tables セクションでテーブルの内容をプレビューできます。
今回は変換後のデータであることを明示するために、attendance_transform というテーブル名としました。
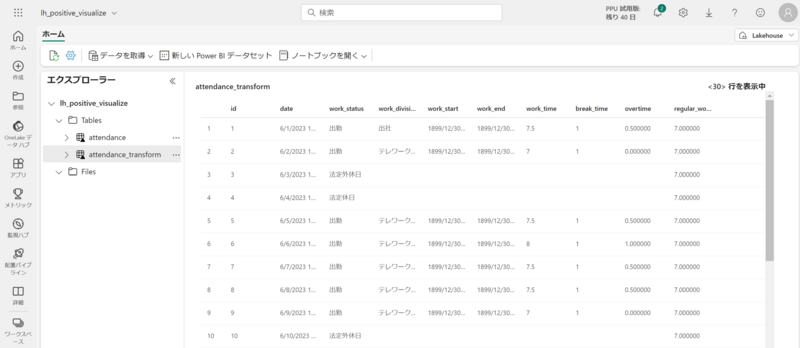
SQL エンドポイントによる分析
データフローから同期されたテーブルに対して分析を実施します。
SQL エンドポイントと呼ばれる機能を利用することで、レイクハウス内のテーブルに対する SQL クエリ発行やリレーションシップの構成が可能です。
レイクハウスの UI より、SQL エンドポイントへ遷移します。
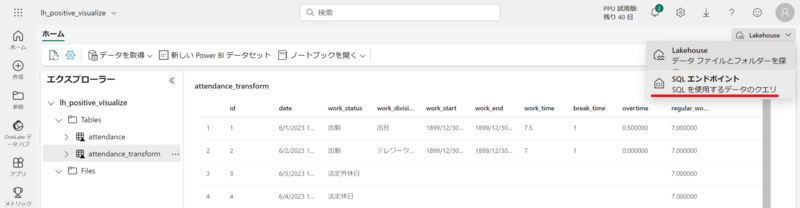
SQL エンドポイントでは 3 つのペインが用意されており、それぞれ下記の作業が可能です。
- データ:スキーマ定義に含まれるテーブルデータの確認や SQL クエリの管理
- クエリ:T-SQL クエリの発行
- モデル:テーブル間のリレーションシップ構成や Power BI におけるメジャーの設定が可能
今回はクエリとモデルのペインにて、それぞれ分析作業を実施しました。
主な分析内容は下記の通りです。
- SQL クエリを利用した分析
- 勤務時間、残業時間、勤務区分、勤務形態の集計
- 勤務形態における勤務状況の傾向分析
- 1 か月間における勤務状況の傾向分析
- モデル
- 勤務日における出社/テレワークの割合を算出
今回は 1 か月分の勤怠データのみであったためそこまで複雑な分析ではありませんが、関連データの追加やデータ期間を拡大することでさらに充実した分析が可能です。
Power BI レポートの作成
最終工程として、分析結果を Power BI で可視化します。
SQL エンドポイント UI の[新しいレポート]より、Power BI レポートの作成画面へ遷移します。

分析結果を反映した Power BI レポートは下画像の通りです。
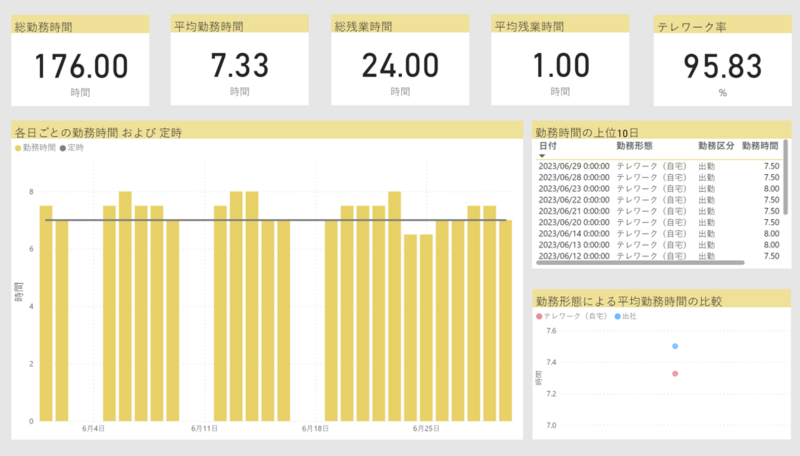
レポート内の各ビジュアルで分析結果を可視化しています。
- 勤務時間と残業時間および勤務日に対するテレワークの割合をカード上にテキスト形式で表示
- 1 か月間における勤務時間の推移と定時に対する残業時間の推移を棒グラフで表示
- 勤務時間が長い日や期間を表形式で表示
- 勤務形態(出社 or テレワーク)の違いで平均勤務時間にどのような影響があるか散布図で表示
サービス検証結果
勤怠データの分析シナリオを通じた Microsoft Fabric の検証結果をまとめます。
検証項目は下記の通りです(再掲)。
- Microsoft Fabric のみでデータ分析を一気通貫で実施できるか
- データ分析の経験があまりないユーザーをサポートする機能が現時点でどの程度実装されているか
- Microsoft Fabric の操作感(Power BI や Data Factory など統合されたサービスがこれまで通り利用できるか)
- その他利用時の注意点
一気通貫のデータ分析
データの格納から可視化まですべて Microsoft Fabric で完結できました。
従来のように分析ごとに用途に応じて PaaS を組み合わせたり、インフラを確保する必要がなく、統一された UI の元で作業ができることはメリットであると言えます。
今回はローカルデータを中心とした分析シナリオでしたが、機械学習やリアルタイム分析など幅広いシナリオに対応できるサービスであるという印象です。
一方で、分析シナリオによっては不要な機能やコンポーネントがあることも事実です。
Microsoft Fabric の利用が最適となる分析シナリオは何か、という点については、金銭面や学習コストの観点も含めて今後のアップデートを追っていく必要があります。
データ分析の経験が浅いユーザーへのサポート
今回の検証で触れた機能の中では、データフローの GUI によるデータ変換処理は比較的ユーザーに易しい設計という印象を受けました。
ですが、それ以外の部分については継続的な強化が必要と感じています。
Microsoft Fabric は「誰もがデータを管理および分析してアクションにつながるインサイトを得られる」というコンセプトを掲げていますが、現状の機能構成はデータ変換や加工・分析等の処理設計をユーザーの知識に依存しています。
今回の検証においては、ノートブックを利用したデータの前処理や SQL エンドポイントによる分析で必要となるコードやクエリの作成は、未経験のユーザーには難易度が高い作業です。
誰もがデータを管理および分析するためにはこのような作業に対するサポート機能が必要で、具体的には下記のような内容を期待します。
- Copilot 機能による各種コードやクエリの自動生成
- One Lake のショートカット機能強化(連携先の拡張など)
- ドキュメントやチュートリアルの充実
Microsoft によると、Azure OpenAI と連携した Copilot 機能が近日公開予定となっておりますので、そちらを注視したいと思います。
各機能の操作感
主観になりますが、既存の PaaS や SaaS から統合された機能については違和感なく操作できました。
ノートブックによる対話形式でのデータ操作やデータフロー周辺の操作は、UI 自体が統合元の Microsoft 製品と大きく変わらないため、それらの経験がある方であれば抵抗なく利用できるかと思います。
まとめ
本記事では、Microsoft Fabric の概要とサービス検証として実施した勤怠データ分析の内容についてご紹介しました。
Microsoft Fabric は発表されて間もないソリューションであり、ロードマップでは今後も多くのアップデートが予定されておりますので、引き続き注視したいと思います。
私たちは一緒に働いてくれる仲間を募集しています!
クラウドアーキテクト執筆:@tamura.kohei、レビュー:@yamada.y
(Shodoで執筆されました)



