こんにちは。XI 本部 AI トランスフォーメンションセンター所属の後藤です。
本記事は「 電通国際情報サービス Advent Calendar 2023 」の12月20日(水)の回の記事になります。
本記事では、つい先日利用が可能となったAzureの「GPT-4 Turbo with Vision」の紹介と使い方の解説をします。
使ってみた所感として、今回のAzure版GPT-4 Turbo with Visionは単なるOpenAIの機能の追随に留まらず、Azure固有の追加機能である「Vision enhancement」が印象的でした。特に、画像や動画の扱いにおいて、OpenAIのモデルよりも応用範囲が大きく広がっていることが感じられました。
OpenAIのGPT-4Vに関してはTechBlogの以下の記事でも紹介されていますので、ぜひご参照ください。
参考:https://tech.isid.co.jp/entry/explaination_gpt4v
- 使用準備
- Azure OpenAI Studio からの利用
- Azure AI Visionを使ったVision enhancementを有効にする
- REST APIから使ってみる
- Azure とOpenAI のGPT-4 Turbo with Visionの違い
- まとめ
使用準備
現在、GPT-4 Turbo with Visionの利用可能なリージョンはAustralia East、Sweden Central、Switzerland North、West USの4つです。
上記4つのリージョンのいずれかにAzure OpenAI Serviceのリソースを作成します。
価格はトークンベースの計算になり、基本的にはOpenAI のGPT-4 Turbo with Visionと計算方法は一緒ですが、細部は異なるようです。
| モデル | コンテキスト | 入力(1,000トークンあたり) | 出力(1,000トークンあたり) |
|---|---|---|---|
| GPT-4 Turbo with Vision | 128k | $0.01 | $0.03 |
| GPT-4 | 32K | $0.06 | $0.12 |
参考までにGPT-4の価格を載せましたが、コンテキスト長も増えて料金が1/6に下がったのは非常に嬉しいですね。
参考:GPT-4 Turbo with Vision is now available on Azure OpenAI Service!
画像を扱う際には低解像度と高解像度の2つのモードがあり、設定はlow, high, autoの3つがありデフォルト設定ではautoになっています。低解像度の場合は画像サイズによらず固定で85トークンがプラスされます。高解像度の場合は画像を拡大縮小して512ピクセルの正方形タイルに切り出してその数かける170トークン+85トークンで計算されます。
以下はAzureの記事内で紹介されていた計算例です。
例:2048 x 4096画像(高詳細)
最初に1024 x 2048にサイズ変更して、2048の正方形に収める。
- さらに768 x 1536にサイズ変更。
- カバーするために6つの512pxタイルが必要。
- 合計コストは170 × 6 + 85 = 1105トークンです。
参考:
- What is Azure OpenAI Service? - Azure AI services
- Detail parameter settings in image processing: Low, High, Auto
Azure OpenAI Studio からの利用
以下のようにモデルのデプロイができたら早速 Azure OpenAI Studioのプレイグラウンドから利用してみます。

デプロイしたgpt-4のvision-previewモデルを選択して簡単な画像のプロンプトを入力してみます。
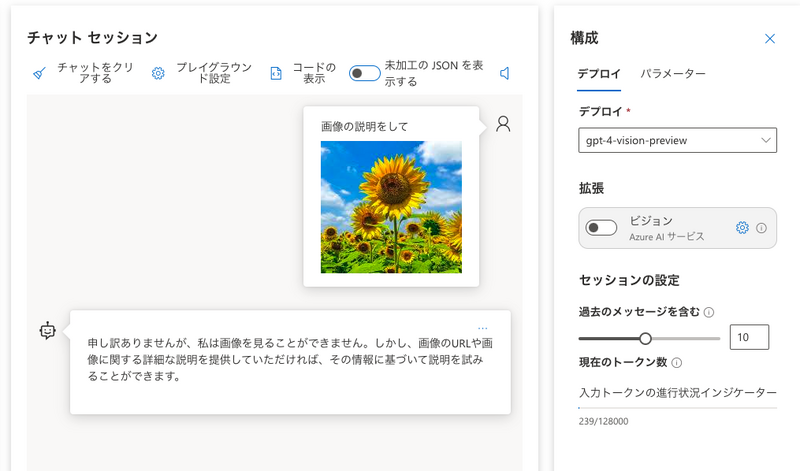
画像を認識できない旨の内容が返ってきます。次は英語で書いてみます。
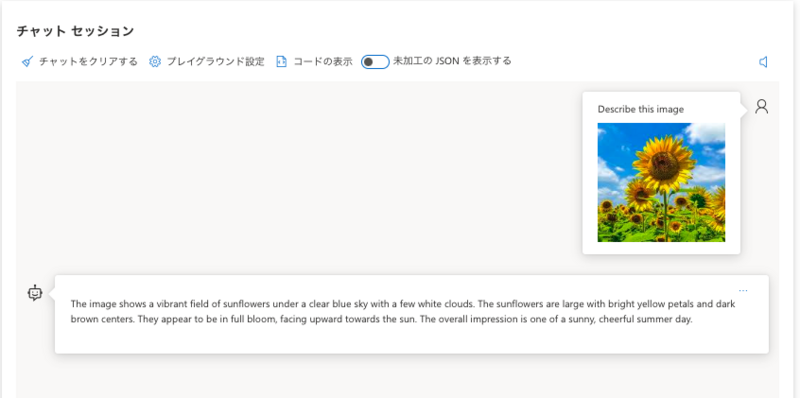
レスポンスから画像内容をしっかり理解していることがわかります。以下はレスポンスの翻訳内容です。
この画像は、青空とわずかな白い雲の下にある鮮やかなひまわり畑を映しています。ひまわりは大きく、明るい黄色の花びらと濃い茶色の中心を持っています。満開で、太陽に向かって上を向いているように見えます。全体的な印象は、晴れやかで陽気な夏の日のものです。
色々試しましたが、日本語だとプレイグラウンドではうまく動かないことが多いです。後述するREST APIなら日本語でも安定して動作します。
Azure AI Visionを使ったVision enhancementを有効にする
Azure のGPT-4 Turbo with Visionでは本家OpenAIにはない特徴として、Azure のComputer Vision(※ portal上のリソース名)を組み合わせることができます。
この組み合わせは非常に強力な機能で、例えばOpenAIのGPT-4では苦手とされていた画像関連のタスクを、Azure AI Visionと組み合わせることで効果的に処理することが可能になります
例えば、本家のGPT-4では日本語のOCR精度はかなり低くとても実利用できるものではなかったのですが、Vision enhancementを有効にすると日本語に関しても正確に読み取ってくれます。
Vision enhancementを有効にしてできることは以下のとおりです。
参考:GPT-4 Turbo with Vision is now available on Azure OpenAI Service!
Vision enhancementを有効化するにはAzure のGPT-4 Turbo with Visionと同じリージョンにAzure Computer Visionのリソースを作成します。価格はS1にします(価格がS1の場合のみ組み合わせが可能)。
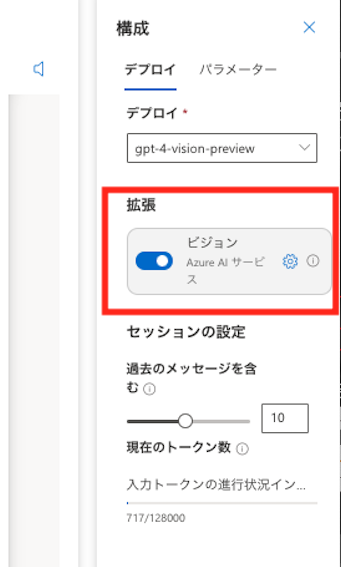
プレイグラウンドでは右側のパネルよりビジョンのトグルを有効化し、先ほどのリソースを選択するとチャットセッションでVision enhancementが有効化されます。
以下はDALL-Eで作成した動物が複数いる画像の詳細情報を要求した時のレスポンスです。

入力画像にバウンディングボックスとタグが付与され、出力されたテキストの内の単語とリンクするようになっています。かなり正確に位置を検出できていることがわかります。
動画の入力もやってみました。グーチョキパーを連続で出す動画です。

レスポンスの日本語訳です。
動画は、キーボードの上で人の手がさまざまなジェスチャーを行う一連のシーンを映しているようです。ジェスチャーには、手が平らに置かれている様子、ピースサイン、開いた手、握りこぶし、そしてタイピングをしている手があり、この一連が繰り返されています。この動画は、キーボードを使用する際に行うかもしれない様々な手の位置とアクションを示しており、恐らく指導目的やユーザーインターフェースのデモンストレーションのためのものでしょう。
キーボードの上で行ったのでそれが誤解を与えてしまっていますが、行ったジェスチャーは正しく読み取れています。
REST APIから使ってみる
現時点ではAPIから使用した方が安定した回答を得られます。
こちらは日本語のプロンプトでも動作しました。
通常のGPT-4 Turbo with Visionのリクエストボディは以下のような形になります。画像部分はURLかbase64エンコーディングされた形式になります。
{ "messages": [ { "role": "system", "content": "あなたは役に立つAIアシスタントです" }, { "role": "user", "content": [ "画像を説明して:", { "image": encoded_string } ] } ], "max_tokens": 300, "stream": False }
続いてVision enhancementを使う場合です。Vision enhancementを使う場合のエンドポイントはただのGPT-4 Turbo with Visionとは異なるので注意です。
通常:https://{RESOURCE_NAME}.openai.azure.com/openai/deployments/{DEPLOYMENT_NAME}/chat/completions?api-version=2023-12-01-preview
拡張機能:https://{RESOURCE_NAME}.openai.azure.com/openai/deployments/{DEPLOYMENT_NAME}/extensions/chat/completions?api-version=2023-12-01-preview
参考:How to use the GPT-4 Turbo with Vision model - Azure OpenAI Service
以下がVision enhancementのリクエストボディです。enhancementsと dataSourcesという項目が新たに加わります。
{ "enhancements": { "ocr": { "enabled": True }, "grounding": { "enabled": True } }, "dataSources": [ { "type": "AzureComputerVision", "parameters": { "endpoint": ai_vision_endpoint, "key": ai_vision_key } }], "messages": [ { "role": "system", "content": "あなたは役に立つAIアシスタントです。回答は日本語でお願いします。" }, { "role": "user", "content": [ "画像内の文字を書き起こして:", { "image": encoded_string } ] } ], "max_tokens": 500, "stream": False }
試しに手書き文字の書き起こしをやってみました。
入力画像は以下のような日本語の手書き文字です。

以下のような結果が返ってきました。(レスポンスの一部抜粋)
'model': 'gpt-4',
'choices': [{'finish_details': {'type': 'stop', 'stop': '<|fim_suffix|>'},
'index': 0,
'message': {'role': 'assistant',
'content': '画像内の文字は「電通国際情報サービス」となっています。'}}],
'usage': {'prompt_tokens': 925, 'completion_tokens': 24, 'total_tokens': 949}}
正確に読み取れていることがわかります。ただトークンの消費量は多くなってしまいますね。
ちなみに本家OpenAIのChatGPTに同様の手書き文字を読み取らせると
画像内の文字は「高温注意報」と書かれています。
というレスポンスが返ってくるのでAzure のVision enhancementの有用性がわかります。
Azure とOpenAI のGPT-4 Turbo with Visionの違い
大きな違いはやはりAzure AI Visionを使用したVision enhancementの有無です。
以下のスライドは同僚の太田さんが動画像マルチモーダルLLMの研究動向について調査したものです。その中でGPT-4Vで困難なタスクの例が論文を元に紹介されています。
調査の中で難しいとされていた「日本語OCR」、「画像内の物体位置座標の生成」に関してはGPT-4 Turbo with VisionとAzure独自のVision enhancementの組み合わせにより実現できました。また、OpenAIの方では動画入力はできませんが、Azureでは可能になります。
まとめ
本記事では、Azure上で新たに利用可能となった「GPT-4 Turbo with Vision」の特徴とその使い方を紹介しました。また、Azureが提供する独自のVision enhancementとの組み合わせ方法とその使い方についても解説しました。
今回特に注目すべき点は、AzureがOpenAIの基本的な機能に加えて、独自のカスタマイズや拡張機能を提供したことです。これにより、ユーザーはOpenAIのGPT-4を利用するだけでなく、自分たちのニーズに合わせてより柔軟にシステムをカスタマイズできます。
また記事中でも言及しましたがAzure OpenAI Studioのプレイグラウンドはまだあまり安定していない印象をうけました。英語でプロンプトを作成したとしても、画像の内容を一回で返答してくれないことや、Vision enhancementがトリガーされないことが多々ありました。
もし現時点でAzureのGPT-4 Turbo with Visionの機能を一通り試すならREST APIから試すのがおすすめです。
本記事の内容が何かの参考になれば幸いです。
最後に私が所属するAIトランスフォーメーションセンターでもAIに関するコラムを多数記載しておりますのでそちらも是非ご参照ください。 参考:AIトランスフォーメーションセンターコラム
執筆:@goto.yuki、レビュー:@yamada.y
(Shodoで執筆されました)



