
こんにちは。エンタープライズ第三本部マーケティングIT部の熊倉です。
このブログでは、高速に動作する分散処理エンジン「Apache Spark」と オープンテーブルフォーマット「Delta Lake」を基盤としたレイクハウス環境を構築できるDatabricks上で管理しているデータセットに対して、名寄せ処理を行うアプローチについて紹介します。
実際のノートブックの処理についても紹介しようと思っていますが、想定よりも内容が多くなってしまったので、名寄せの概要を紹介する「概要編」、ソースコードなど具体的な名寄せ処理の具体的な内容を紹介する「決定論的マッチング編」「確率的マッチング編」の三部作にしようと思います。
本記事は概要編で、名寄せ処理について概要、Databricksで名寄せ処理を行うメリットについて紹介します。
名寄せ処理の基本をご存知の方は、本記事を読み飛ばしていただき、「決定論的マッチング編」または「確率的マッチング編」からお読みいただいても構いません
1. はじめに
1.1 名寄せとは
複数のレコードから、同一のエンティティ(現実世界で一意の顧客や製品など)を特定する操作を名寄せ(英語だとEntity Resolution等)と呼びます。
1つのデータセット内で発生している重複を解消する場合や、共通IDが存在しない複数のデータセット間でユニークなエンティティを特定したい場合に名寄せ処理は実施されます。
エンティティは、企業が個別の単位として測定したいものなら何でも該当します。
(例えば、B2C企業だと「顧客」や「製品」、「サブスクリプション」、B2B企業だと「チーム」「企業」などが挙げられます)
1.2 Entity Resolution と Identity Resolution
エンティティが「顧客」の場合の名寄せは、アイデンティティ解決(Identity Resolution)とも呼ばれることもあります。
アイデンティティ解決の主要な目的の一つは、顧客に関するあらゆる情報を統合し、多角的な顧客理解を可能にする「カスタマー360」(360度顧客ビュー)の構築です。これの実現は、マーケティング効果の向上、顧客体験の最適化、効率的な顧客対応に不可欠です。
歴史的に見ると、このための機能は、金融機関における初期の顧客情報システムであるMCIFのようなデータベースマーケティングシステムから始まり、その後、CRM、CDPといった様々なシステムで開発・実装されてきました。
1.3 日本の名寄せ処理事情
日本の情報が格納されたデータセットに対して名寄せを行いたい場合、日本語特有の課題が存在します。
例えば、
- ひらがな、カタカナ、漢字と文字の種類が多いこと
- 例(類似度について)
- 例えば、「Robert」と「Robelt」という文字列ペアと、「渡邉」と「渡辺」という文字列ペアは、どちらも編集距離(ここでは、1文字置換のコストを1とします)は同じ1です。しかし、単純に「編集距離/文字列長」で誤り率を評価すると、「Robert / Robelt」(6文字中1文字の違い)は約16.7%ですが、「渡辺/渡邉」(2文字中1文字の違い)は50%となり、後者の方が不一致度が大きく評価される傾向があります。このように、短い文字列(特に漢字2文字など)では、1文字の違いが全体に与える影響が相対的に大きくなってしまいます。
- 漢字については複数の読み方が存在しており、ふりがなの変換も難しいこと
- 例: 東海林(とうかいりん、しょうじ)など
- 例(類似度について)
- 住所の体系がかなり複雑なこと
- 日本の住所の正規化、名寄せの難易度の高さについて度々取り上げられ話題になります。
1.4 国内の名寄せソリューション
上記のような理由で日本語での名寄せは他の言語に比べると難しい傾向にあります。そのため、国内では従来よりゴールデンレコード(信頼できるソース)となる辞書データを所有しており、データの正規化を行える企業が名寄せソリューションを提供してきた背景があります。
例: 中小企業の辞書データを所有する企業が提供する会社の名寄せソリューションや、住所辞書を所有する企業が提供する人の名寄せソリューションなど
2. 名寄せ処理の概要
2.1 名寄せ処理のステップ
名寄せ処理のステップは大きく 「対象データの分析」「名寄せの計画・設計」「対象データの前処理」「対象データのマッチング」に分かれます。
対象データの分析
名寄せの計画・設計
名寄せ処理のスケジュールや目的を設定します。目的によって、名寄せ処理の誤りをどの程度許容できるか(あるいは全く許容できないか)が異なるため、あらかじめ明確に定義し、関係者間で合意を得ておくことが必要です。
また、ルールベースで名寄せ処理を行う場合、この段階で名寄せルールを定めます。
例)氏名と生年月日、住所が一致した場合は同一人物とする
対象データの前処理
データの内容は基本的に直接改変せず、後述のマッチング処理を効率良く行うために、表記揺れを吸収するようなデータの整形を行います。ただし、豊富な辞書データ(正本データ)を保有する従来型名寄せサービスなどでは、この段階で正本データに基づき表記の修正まで実施することもあります。
対象データのマッチング
前処理が完了した対象データに対してマッチング処理を行います。
また、対象データに対してマッチング処理を行った結果、(一般的には)同一とされたエンティティに対して新しいユニークなIDを付与します。
マッチング手法にはルールベースの決定論的マッチングとエンティティの一致度を確率で表現する確率論的マッチングが存在します。これらの詳しい処理内容については後述します。
2.2 偽陽性と偽陰性
ある情報を”分類”する際、その予測結果と実際の値(正解)パターンは以下の4つに分類できます。
- 真陽性 (True Positive, TP):
- 実際に陽性であるものを正しく陽性と予測できたケース
- 例: 実際に同一人物のレコードを同一人物と判断
- 実際に陽性であるものを正しく陽性と予測できたケース
- 真陰性 (True Negative, TN):
- 実際に陰性であるものを正しく陰性と予測できたケース
- 例: 実際に別人物のレコードを別人物と判断
- 実際に陰性であるものを正しく陰性と予測できたケース
- 偽陽性 (False Positive, FP):
- 実際には陰性であるものを、誤って陽性と予測してしまったケース
- 例: 実際は別人物なのにレコードを同一人物と判断
- 実際には陰性であるものを、誤って陽性と予測してしまったケース
- 偽陰性 (False Negative, FN):
- 実際には陽性であるものを、誤って陰性と予測してしまったケース
- 例: 実際は同一人物なのにレコードを別人物と判断
- 実際には陽性であるものを、誤って陰性と予測してしまったケース
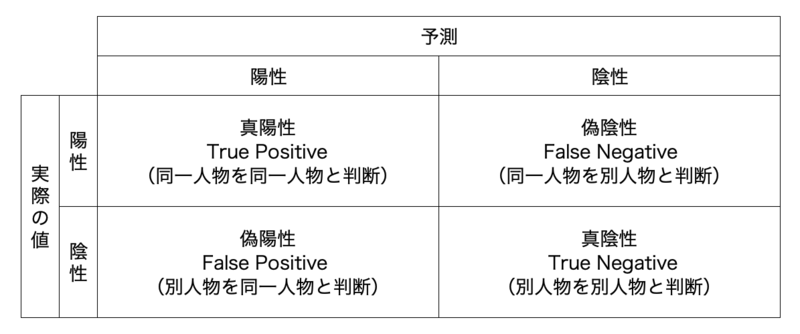
名寄せの目的によって、偽陽性と偽陰性のどちらを許容するか(反対に許容できないか)を合意しておくことが重要です。
2.3 決定論的マッチングと確率的マッチング
マッチングの手法は大きく、決定論的マッチングと確率論的マッチングの 2 種類に分かれます。
1. 決定論的マッチング
決定論的マッチングは、ルール(条件)を定義し、エンティティを同一と見なす名寄せ手法です。
- 主な特徴
- ルールベースのマッチング
- 事前に定義された厳格なルール(例:「氏名と生年月日が完全に一致する」「メールアドレスが完全に一致する」など)に基づいてレコードを比較し、条件に合致した場合にのみ同一エンティティと判断します。
- ルールベースのマッチング
- 利点
- 高精度
- 誤判定(偽陽性)が少なく、信頼性が高いです。特にパーソナライズされたコミュニケーションなど、精度が重視される用途に適しています。
- 計算コスト
- 確率的モデルと比較して、ルールベースのマッチングは計算量が少なく済む場合があります。
- 解釈可能性
- なぜデータが結びつけられたのか、ルールに基づいて明確に説明できます。
- 高精度
- 欠点・課題
- まとめ
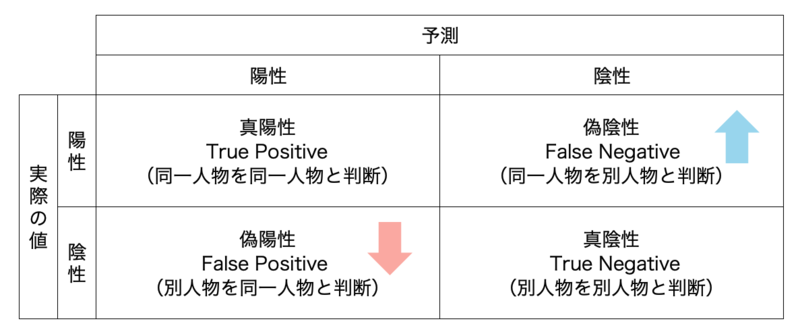
決定論的マッチングは、明確な情報に基づいて高い精度で顧客情報を統合する強力な手法ですが、データの完全性や表記の揺れに弱く、すべての関連データを見つけ出す(再現率) 点では限界があることを理解して利用する必要があります。
2. 確率的アイデンティティ解決
確率論的名前解決とは、ルールに一致するかどうかだけに頼るのではなく、複数の情報や不完全な情報を統計的に評価し、異なるレコードが同じエンティティを指している「確率」を計算する手法です。
あいまい一致(Fuzzy Matching)と呼ばれることもあります。
- 主な特徴
- 証拠に基づくアプローチ
- 氏名、生年月日、住所、メールアドレス、位置情報など複数の属性や情報の一致率を算出し、「証拠」として利用します。
- 単一の属性(例:氏名が同じ、メールアドレスが同じ)だけでは一致と判断せず、複数の証拠を組み合わせ総合的に評価します。
- 各属性の一致・不一致が、どの程度「同一エンティティである」という結論を支持するか(または否定するか)を重み付けし、総合的な一致確率を算出します。
- 例えば 、
「田中 一郎、生年月日1990/05/09、郵便番号000 1234」というレコードと、
「田中 市朗、生年月日1990/05/09、郵便番号AB12 3CD」というレコードがあった場合、
名前は完全一致しないものの、他の属性が一致しているため、一致確率(例:98.21%)は高い
のように確率をそれぞれ算出します。
- 例えば 、
- 閾値の設定を後から設定でき、柔軟性がある
- 証拠に基づくアプローチ
- 利点
- (ルールベースの決定論的マッチングに比べ)より多くのレコードを検出できる
- 実際にマッチングされた結果を見ながら、同一かどうかの判断ができる
- 欠点・課題
- まとめ
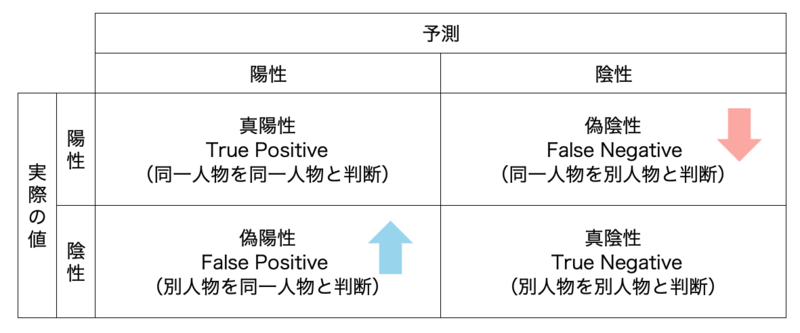
確率論的名前解決は、複数の不確実な情報から統計的に同一性を推定する柔軟なアプローチであり、より多くのデータを統合できる可能性がありますが、メリットとデメリットを理解し、閾値をどこに設定するかが重要となる手法です。
決定論的マッチングと確率的マッチングの選択
上記のように、決定論的マッチングと確率的マッチングではそれぞれメリットデメリットが存在しており、どちらに優位性があるという訳ではありません。
例えば、名寄せした結果を基にユーザーに対してメールや電話による1on1の施策を行いたい場合、別人同士を同一人物として判断してしまう偽陽性が許容されないため、ルールベースの決定論的マッチングが適しています。一方、広告のオーディエンスとして利用するなど、ある程度の誤りが許容できる場合(機会損失の方が大きいと考えられる場合)は、確率論的マッチングの方が適しています。
名寄せした結果どうしたいか(どのような利用を想定しているか)によって、どちらかを選択したり、あるいは組み合わせて(氏名、住所、電話番号が一致する人は決定論的な考え方で同一人物とするが、他の属性の組み合わせについては確率的な考え方で名寄せを行うなど)名寄せ処理を行なっていくことになります。
3. Databricks上での名寄せ
3.1 Databricksの利用
Databricksは、Apache Sparkを基盤とする統合データ分析プラットフォームで、データエンジニアリング、SQLやPythonを利用した分析、機械学習、AIモデル開発といったデータ関連のワークロードを一元的に提供するプラットフォームです。
Databricksはデータエンジニアリングを行う主要なインターフェースの一つとしてNotebook環境を提供しています。
NotebookではPythonやScala、SQLなどがサポートされており、これらの言語を使用し、データを操作したり分析したりすることができます。
また、膨大なPythonライブラリ(pandas、NumPy、scikit-learn、TensorFlow、PyTorch等)をシームレスに利用することも可能で、名寄せ処理においては、企業がサービスとして提供しているもの以外に、OSSとして利用可能なライブラリも存在するため、それらを活用することでDatabricks上で名寄せ処理を実現できます。
Databricks上で名寄せ処理を行うメリットとして次のようなものがあります。
3.2 テックブログで取り上げるライブラリ
「決定論的マッチング編」「確率的マッチング編」では実際にDatabricksで名寄せ処理を実装する例を紹介していきます。
名寄せのライブラリについては決定論的マッチングでは「Splink」、確率的マッチングでは「Zingg」というライブラリを使用していきたいと思います。
どちらもSpark上で動作する機械学習を活用した名寄せライブラリで、確率的マッチングを行うことができます。
(Splinkについてはルールベースの決定論的マッチングも実施可能なので、決定論マッチングの例で利用しています)
教師なし学習によるアプローチをとるのがSplink、教師あり学習によるアプローチを取るのがZinggとなっています。
Splink
教師データなし学習によるアプローチを取っており、氏名、住所、生年月日といった複数の属性情報に対し、一致・不一致を判断する信頼度による重み付けを行い、2つのレコードの一致確率を算出(≒ 名寄せ)することができます。
「Fellegi-Sunter」モデルという理論に基づいて2つのレコードの一致確率を求めるのですが、その中でパラメータチューニング作業が求められるため、実装としてはやや難易度が高くなる傾向にあります。(実装には「Fellegi-Sunter」モデルの理解、基本的な機械学習の理解、そのデータセットの理解が必要)
メインとなる名寄せ処理(モデル作成など)以外に名寄せマッチングに必要な分析機能なども提供されており、名寄せのステップでいう対象データの分析を行うAPIが用意されています。
Databricksでは以前、ARC(Auto Record Linkage)というレコードの名寄せを行えるライブラリが提供されていました。
内容としてはSplinkをラップし、Databricks利用に特化したものだったようですが、現在更新が停止しており、利用が非推奨となっています(代わりにSplinkを直接使って欲しいと記載あり)
- https://www.databricks.com/blog/improving-public-sector-decision-making-simple-automated-record-linking
- https://github.com/databricks-industry-solutions/auto-data-linkage
Zingg
Zinggは、機械学習(ML)を活用したオープンソースの名寄せ(エンティティ解決)ライブラリです。
顧客、製品、サプライヤーなど様々なエンティティに対応し、異なるデータソース間や単一データソース内の重複レコードや同一実体を特定・結合できます。
名寄せ処理のステップは少しユニークで、対象となるデータセットからまずラベリングを行い(2レコードが同一か別かを判断)、ラベリングした教師データを元にトレーニングを行い、モデルを作成し、実際のデータセットに対して名寄せを行う、といった流れを取ります。
DatabricksやSnowflake、Cassandra、S3、Azure、主要RDBMSなど、多くのデータソースやファイル形式(Parquet, Avro, JSON, CSVなど)に対応しており、特にDatabricksに関しては、すぐにDatabricks上で処理を実行できるNotebookのサンプルなども提供されています。
Databricksが提供する特定のユースケースに特化したテンプレート(ソリューションアクセラレーターと呼ばれます)で利用されていたり、AWSの公式ブログやHightouchのドキュメントで取り上げられるなど、(名寄せライブラリの中では)比較的知名度の高いライブラリとなっています。(GitHub stars 1k)
- https://www.databricks.com/jp/solutions/accelerators/product-matching-with-ml
- https://aws.amazon.com/jp/blogs/big-data/entity-resolution-and-fuzzy-matches-in-aws-glue-using-the-zingg-open-source-library/
- https://hightouch.com/blog/what-is-entity-resolution
「Databricksで実現するデータ名寄せ【概要編】」については以上になります。
本記事が名寄せ処理を理解する上で、少しでもお役に立てれば幸いです。
「決定論的マッチング編」、「確率的マッチング編」では実際にDatabricks上で実装する例について紹介しますので、こちらもぜひご覧ください!
以上、最後までご覧いただきありがとうございました。
執筆:@kumakura.koki、レビュー:@akutsu.masahiro
(Shodoで執筆されました)



