
はじめに
スマートソサエティセンターの飯田です。
Googleの生成AI「Gemini」を音声通話と組み合わせ、電話対応の負担を抑えるプロトタイプを作ってみました。
本記事では、その取り組みと、そこから見えてきた生成AI活用の具体的な可能性についてご紹介します。
背景:深刻化する電話業務の負担と、DXによる解決への期待
顧客からの理不尽な要求や迷惑行為は、近年深刻な社会問題となっています。
従業員の精神的な負担増大や離職率の上昇を引き起こし、企業経営にとって看過できない問題となっています。
このような状況を受け、各企業には電話業務軽減への具体的な対策強化が急務となっています。
厚生労働省も対策の重要性を指摘し、「カスタマーハラスメント対策企業マニュアル」を公開するなど、社会全体での取り組みが進められています。
(参考:厚生労働省 カスタマーハラスメント対策企業マニュアル)
Geminiを音声コミュニケーションと連携させ、電話対応業務の負荷を下げるプロトタイプを2つ作ってみました!
開発したプロトタイプ1:Geminiと電話で会話できるシステム
デモはこちら
https://youtube.com/shorts/sWuTqs8g_gU
電話システムとGeminiを直接連携させたプロトタイプを開発しました。
電話応対業務は感情労働の側面が強く、AIによる一次対応やオペレーター業務の一部代替は、
従業員の負担軽減と業務効率化に繋がるといいなという想いでつくりました。
このシステムの構成はシンプルで、以下のような形です
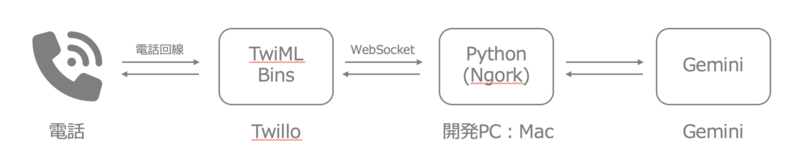
- 電話回線: ユーザーからの電話
- Twilio: 電話回線とWebアプリケーションを接続するためのPaaS。着信処理や音声ストリームの制御。
今回はTwiML Binを利用。https://www.twilio.com/ja-jp - WebSocket (WS): Twilioとバックエンドアプリケーション間でリアルタイムな双方向通信を確立。
- バックエンドアプリケーション (Python on ngrok): WebSocket経由でTwilioから音声データを受け取り、Gemini APIへ連携。開発段階では、ローカル環境を外部公開するために
ngrokを使用。 - Gemini: 受け取ったテキストに基づき、自然な応答メッセージを生成し、音声合成(別途実装想定)を通じてユーザーへ返す。
技術的考察と今後の課題:
実装してみたところ、現時点では、Geminiのリアルタイム性を最大限に活かすためのGemini LIVE API などの連携を完全に最適化できないので、若干の応答遅延が発生するケースが見られました。
また、UXの観点からも、より自然でスムーズな対話を実現するためには改善の余地があります。
TwilioからWebSocket経由で音声データを受け取るまでの区間にも遅延要因は存在するため、
システム全体のレイテンシを低減するには、ネットワーク設計を含めた総合的な最適化が求められるでしょう。
これらの課題解決は、実用的なAI電話応対システムを構築するうえで重要なポイントとなると思います。
また、以下のようなところも工夫の余地がありそうです
RAG (Retrieval Augmented Generation) の活用: 社内マニュアルや過去の対応事例といった独自の知識ベースをGeminiと連携させることで、より文脈に即した的確な深刻度判定や、オペレーターへの具体的な対応アドバイス生成など、高度な機能実装が期待できます。
Context Caching の最適化: 対話の文脈情報を効率的にキャッシュし再利用することで、Geminiへのリクエストを最適化し、特にリアルタイム性が重視される検知システムにおける応答速度の向上に寄与する可能性があります。
開発したプロトタイプ2:リアルタイムのオペレーター負担検知Webアプリケーション
オペレーターと顧客の会話をリアルタイムで分析し、職員負担の兆候を即座に検知するWebアプリケーションも作ってみました。
このシステムは、従業員の保護を強化するとともに、応対品質の向上にも寄与することを目的としています。会話内容からGeminiがオペレーターの負担の深刻度や原因を推論し、オペレーター支援や早期対応に繋がります。
主な機能と特徴:
- リアルタイム音声認識とテキスト化 ブラウザのマイクを通して入力された音声をリアルタイムでテキストに変換。
- Geminiによる深刻度判定: 変換されたテキストをGeminiに送信し、会話内容に基づいて「深刻度」と「原因の分類」を推論。状況の客観的な把握を支援。
- アラート通知: オペレーター判定の深刻度が高い場合には、管理画面や担当者にアラートを通知し、迅速な介入やエスカレーション。
このWebアプリケーションは、主にフロントエンド技術で構築されており、処理フローは以下のとおりです。

- 音声取得: ブラウザの
Web Speech APIを利用してユーザーの音声をリアルタイムに取得。 - 音声認識 (Speech-to-Text): 同じく
Web Speech APIの機能で、取得した音声をテキストデータに変換。 - 負担度判定: テキストデータをGemini APIに送信し、負担度の判定(深刻度、原因分類など)をリクエストします。この際、プロンプトには定義や判断基準となる事例をFew-shotとして含めることで、判定精度の向上を図っています。
- 結果表示とアラート: Geminiからのレスポンスに基づき、負担度の判定結果を画面に表示。一定以上の深刻度と判定された場合には、アラートを発する仕組み。
まとめ:音声通話とGeminiが開くDXと、より良い顧客コミュニケーションの未来
本記事で紹介したプロトタイプは、音声コミュニケーションとGeminiをはじめとする生成AI技術の組み合わせが持つワクワク感を伝えられたと思います。
顧客コミュニケーション基盤のDXを推進し、同時にオペレーターの負担対策という喫緊の課題にも対応できる大きな可能性が見えてきました。
同様の課題認識を持つ方々や、新たな技術活用を模索されている方々にとって、何らかの参考となれば幸いです。
従来は定量化や即時対応が難しかったコミュニケーションの内容や感情の機微を、Geminiがリアルタイムに分析・評価することで、
電話応対業務の大幅な効率化、従業員の負担軽減、そしてデータに基づいた顧客満足度の向上といったDXの具体的な成果が期待できます。
さらに、様々な社内システムや顧客データと連携することで、業務プロセス全体の変革や、新たな顧客価値の創出など、DXのさらなる深化が期待できるのではないでしょうか。
音声コミュニケーションは、AIとの融合によって、よりインテリジェントで価値あるものへと進化を遂げるでしょう。
皆さんは、Geminiのような生成AIと音声通話を組み合わせることで、どのような業務変革や新しい価値創造が生まれると考えますか?ぜひ、ご意見やアイデアをお聞かせください!
最後まで読んでいただき、ありがとうございました。
↓ のスターを押していただけると嬉しいです。励みになります。
執筆:@iida.michitaka7b3a3dd24e9c454b
(Shodoで執筆されました)



