
こんにちは。電通総研の金融IT本部(兼XI本部)の上野です。 本記事は電通総研 Advent Calendar 2025 11日目の記事です。
最近一番嬉しかったことと言えば、AWSのコンソール検索で「ECR」と入力すると一発と入力するとコンテナレジストリへ飛べるようになったことです。
「ECSからの遷移」や「container registry」と検索していたのは私だけではないはずです。
さて、本日は最近登場したTanStackエコシステムの一つ、TanStack AIを利用してチャットボットを作ってみました。様々なエコシステムで知られるTanStackですが、AIアプリケーション開発の分野に参入していました。
本記事では、TanStack AI の特徴や Vercel AI SDK との違いを解説し、Amazon Bedrock と組み合わせてファイル添付対応のチャットボットを構築する方法を紹介します。
TanStack AIとは
TanStack AI は、複数の AI プロバイダーに対応した統一インターフェースを提供するオープンソース SDK です。TanStack AI Alpha: Your AI, Your Wayにおいて「AI ツールのスイスを目指す」と述べており、「特定のベンダーやプラットフォームに依存しない中立的な設計を意識して作られた」という意味だと理解しています。
TanStack AI takes a different approach. We're building the Switzerland of AI tooling. An honest, open source set of libraries (across multiple languages) that works with your existing stack instead of replacing it.
主な特徴
- ベンダーロックインなし: OpenAI、Anthropic、Google Gemini、Ollama など複数のプロバイダーに対応
- 完全な型安全性: TypeScript でエンドツーエンドの型安全を実現
- フレームワーク非依存:React、Solid、Vanilla JS など任意の環境で利用可能
- マルチモーダル対応:テキスト、画像、音声、動画、ドキュメントをサポート
- MIT ライセンス: 完全なオープンソース
TanStack AI が生まれた背景
TanStack の創設者 Tanner Linsley 氏は、既存の AI SDK(Vercel AI SDK) に対する懸念から TanStack AI を開発しました。
TanStack AI は、これらの課題を解決する「中立的な」SDK として設計されています。Cloudflare や Netlify がスポンサーとして参加しているのも、オープンで移植可能なツールが彼らのプラットフォームにも恩恵をもたらすからだと考えています。
TanStack AI vs Vercel AI SDK
| 項目 | TanStack AI | Vercel AI SDK |
|---|---|---|
| 哲学 | 中立・オープンソース | Next.js/Vercel エコシステム統合 |
| プロバイダー数 | 4(OpenAI, Anthropic, Gemini, Ollama) | 多数 |
| ストリーミング制御 | ステート管理して明示的に管理 | HTTP ストリーム生成までを強くサポート |
| 成熟度 | アルファ版(2025年後半〜) | 安定版 |
| デプロイ先 | どこでも(AWS, Cloudflare, Netlify 等) | どこでも、ただしVercel 最適化 |
現時点では圧倒的にVercel AI SDKが高機能ですが、Vercel提供のSDKはどうしてもプラットフォーム依存部分が出てきます。 標準OSSとして利用可能ではありますが、Next.jsと密接に統合されており、Vercelデプロイ時に最適化されています。例えばVercel Functionsのタイムアウト指定などもセットで利用可能になっている等、Vercelデプロイしない場合は不要な機能がいくつかあります。
TanStack AI を選ぶべきケース
- Vercel 以外の環境(AWS、Cloudflare 等)にデプロイする
- 将来的にプロバイダーを切り替える可能性がある
- TanStack エコシステムを使用している
Vercel AI SDK を選ぶべきケース
- Next.js + Vercel で開発している
- 今すぐ本番環境で使いたい(TanStack AI はまだアルファ版)
- 多数のプロバイダーに対応したい
- 豊富なドキュメントと事例が必要
TanStack AI の実装例
クライアント実装例
import { useChat } from '@tanstack/ai-react' import { fetchServerSentEvents } from '@tanstack/ai-react/connection' function Chat() { const { messages, sendMessage, isLoading } = useChat({ connection: fetchServerSentEvents('/api/chat'), }) const handleSubmit = (e: React.FormEvent) => { e.preventDefault() const input = e.currentTarget.querySelector('input') if (input?.value) { sendMessage(input.value) input.value = '' } } return ( <div> <div className="messages"> {messages.map((msg) => ( <div key={msg.id} className={`message ${msg.role}`}> {msg.content} </div> ))} </div> <form onSubmit={handleSubmit}> <input type="text" placeholder="メッセージを入力..." /> <button type="submit" disabled={isLoading}>送信</button> </form> </div> ) }
サーバー実装例
import { chat, toStreamResponse } from '@tanstack/ai' import { openai } from '@tanstack/ai-openai' export async function POST(request: Request) { const { messages } = await request.json() const response = await chat({ provider: openai({ apiKey: process.env.OPENAI_API_KEY }), model: 'gpt-4o', messages, }) return toStreamResponse(response) }
Vercel AI SDKの利用例(比較用)
- TanStack AIとの差分
- submit時の
sendMessage(input.value)相当の処理は、useChatフックがよしなにやってくれる。
- submit時の
クライアント側の実装例
import { useChat } from 'ai/react' export function Chat() { const { messages, input, handleInputChange, handleSubmit, isLoading, } = useChat({ api: '/api/chat', }) return ( <div> <div className="messages"> {messages.map((msg) => ( <div key={msg.id} className={`message ${msg.role}`}> {msg.content} </div> ))} </div> <form onSubmit={handleSubmit}> <input type="text" placeholder="メッセージを入力..." value={input} onChange={handleInputChange} /> <button type="submit" disabled={isLoading}> 送信 </button> </form> </div> ) }
サーバー側の実装例
import { streamText } from 'ai'
import { openai } from '@ai-sdk/openai'
export async function POST(req: Request) {
const { messages } = await req.json()
const result = streamText({
model: openai('gpt-4o'),
messages,
})
// ストリーミングレスポンスをそのまま返す
return result.toDataStreamResponse()
Amazon Bedrock とは
Amazon Bedrockは、AWSが提供するフルマネージド AI サービスです。Anthropic Claude、Meta Llama、Amazon Titanなど、複数の基盤モデルを統一されたAPIで利用できます。
Amazon Bedrock の特徴
- マルチモデル: 複数ベンダーのモデルを同一 API で利用
- IAM 統合: AWS の認証・認可基盤を活用
- VPC 対応: PrivateLink でセキュアな接続
- リージョン: 東京(ap-northeast-1)で利用可能
- 従量課金: AWS 請求に統合、予測可能なコスト管理
Amazon Bedrock を使うメリット
- AWS の IAM による認証・認可を利用したい
- VPC PrivateLink でセキュアな接続をしたい
- AWS の請求に統合してコスト管理をしたい
- CloudTrail でアクセスログを取得したい
他のクラウド AI サービスとの比較
マルチモデル AI サービスは各クラウドベンダーが提供しています。AWS の Bedrock、Google Cloud の Vertex AI、Microsoft の Azure AI Foundry(旧 Azure AI Studio)を比較してみます。
※名称や提供モデル・機能は逐次変化するため、公式の情報を参照してください。
利用可能なモデル
| プロバイダー | Amazon Bedrock | Vertex AI | Azure AI Foundry |
|---|---|---|---|
| Anthropic Claude | ✅ Claude 4, 3.5, 3 系 | ✅ Claude 3.5, 3 系 | ❌ |
| OpenAI GPT | ❌ | ❌ | ✅ GPT-4o, GPT-4, GPT-3.5 |
| Google Gemini | ❌ | ✅ Gemini 2.0, 1.5 | ❌ |
| Meta Llama | ✅ Llama 3系 | ✅ Llama 3系 | ✅ Llama 3系 |
| Mistral | ✅ Mistral Large, Small | ✅ Mistral | ✅ Mistral Large |
| 自社モデル | Amazon Nova, Triton | Gemini | Phi-4, Phi-3 |
主な機能比較
| 機能 | Amazon Bedrock | Vertex AI | Azure AI Foundry |
|---|---|---|---|
| 統一 API | Converse API | Gemini API / Model Garden | Azure OpenAI + Azure AI Inference |
| ファインチューニング | 可 | 可 | 可 |
| RAG 機能 | Knowledge Bases | Vertex AI Agent Builder(統合中?Vertex AI Search) | Azure AI Search 連携 |
| エージェント | Bedrock Agents | Vertex AI Agent Builder | Azure AI Foundry Agent Service |
| ガードレール | Guardrails for Bedrock | Responsible AIツール群 | Content Safety |
※ファインチューニングはモデルによって可不可があります。
選定の指針
現時点ではモデルベースで利用基盤を選ぶことになるかと思います。
実際は各サービスのモデルカタログを見ながら、要件にあったモデルが使えるかどうか、対象のリージョンで提供されているかどうかを加味して比較する必要があります。
- Claude を使いたい:Amazon Bedrock または Vertex AI
- OpenAI GPT を使いたい:Azure AI Foundry
- Gemini を使いたい:Vertex AI
今回は使い慣れた AWS 環境で Claude を利用したかったため、Amazon Bedrock を選択しました。
TanStack AI × Amazon Bedrockとの接続
TanStack AI と Amazon Bedrock を接続する方法を説明する前に、TanStack AI の 2 層構造+呼び出すAIプロバイダーで、合計3つの役割に分かれていることを理解する必要があります。
- クライアント層
- useChat + Connection Adapter (SSE/HTTP/WebSocket)
- SSE ストリームのリクエストとレスポンスハンドリング
fetchServerSentEvents、fetchHttpStreamなど
- サーバー層
- chat() + Provider Adapter (OpenAI/Anthropic/etc)
@tanstack/ai-openai、@tanstack/ai-anthropicなど
- AI プロバイダー
- OpenAI / Anthropic / Google Gemini / Ollama
- サポートされていない場合は自前で実装が必要
TanStack AI は現在アルファ版であり、公式にサポートされているAIプロバイダーは以下の 4 つです:
- OpenAI (
@tanstack/ai-openai) - Anthropic (
@tanstack/ai-anthropic) - Google Gemini (
@tanstack/ai-gemini) - Ollama (
@tanstack/ai-ollama)
Amazon Bedrock 用のアダプターは公式には提供されていません。Anthropic の Claude を使いたい場合、@tanstack/ai-anthropic で直接 Anthropic API に接続することは可能ですが、Amazon Bedrock 経由で利用したい場合はカスタムアダプターを実装する必要があります。
TanStack AIは公式にカスタム可能と謳っているため、本来クライアント層/サーバー層ともに Bedrockのアダプターを作成して接続したかったのですが、TanStack AIが未だα版であり、公開情報も少ないためにサーバサイドは自前で接続処理を設けます。
今回の実装方針は以下のとおりです。
- サーバー側:Amazon Bedrock SDK を直接使用し、TanStack AI の
StreamChunk形式で通信する - クライアント側:TanStack AI の
useChatフック + カスタム Connection Adapter でレスポンスを受け取る
この方法により、TanStack AI の useChat フックの恩恵(メッセージ管理、ローディング状態、型安全性)を受けながら、Amazon Bedrock と接続できます。
サーバー側の実装例
Amazon Bedrock アダプタークラス
AWS SDK を使用して Amazon Bedrock の Converse API を呼び出し、TanStack AI の StreamChunk 形式でストリームを返します。
import { BedrockRuntimeClient, ConverseStreamCommand, } from '@aws-sdk/client-bedrock-runtime' export interface StreamChunk { type: 'content' | 'thinking' | 'done' | 'error' id?: string model?: string timestamp?: number delta?: string // 増分トークン content?: string // 累積コンテンツ role?: string // 'assistant' finishReason?: string error?: string } // Adapterと言っているが、TanStack AIとのアダプタではなく単にawsのsdkから接続するBedrockへのAdapter export class BedrockAdapter { private client: BedrockRuntimeClient private modelId: string async *chatStream(messages, options): AsyncGenerator<StreamChunk> { const command = new ConverseStreamCommand({ modelId: this.modelId, messages: this.formatMessages(messages), additionalModelRequestFields: options.enableThinking ? { thinking: { type: 'enabled', budget_tokens: 5000 } } : undefined, }) const response = await this.client.send(command) for await (const event of response.stream!) { if (event.contentBlockDelta?.delta) { const delta = event.contentBlockDelta.delta if ('thinking' in delta) { yield { type: 'thinking', delta: delta.thinking, ... } } else if ('text' in delta) { yield { type: 'content', delta: delta.text, role: 'assistant', ... } } } if (event.messageStop) { yield { type: 'done', finishReason: 'end_turn' } } } } }
Express サーバー
Bedrock アダプターを使用し、SSE 形式でクライアントに送信します。
import express from 'express' import { bedrock } from './adapters/bedrock-adapter.js' const app = express() const adapter = bedrock({ region: process.env.AWS_REGION || 'us-east-1', modelId: process.env.BEDROCK_MODEL_ID || 'claude-sonnet-4', }) app.post('/api/chat', async (req, res) => { const { messages } = req.body // SSE ヘッダー設定 res.setHeader('Content-Type', 'text/event-stream') res.setHeader('Cache-Control', 'no-cache') res.setHeader('Connection', 'keep-alive') const stream = adapter.chatStream(messages, { systemPrompt: 'Hello World', enableThinking: true, }) for await (const chunk of stream) { res.write(`data: ${JSON.stringify(chunk)}\n\n`) if (chunk.type === 'done' || chunk.type === 'error') break } res.end() })
クライアント側の実装例
カスタム Connection Adapter
TanStack AI の ConnectionAdapter インターフェースを実装し、サーバーからのレスポンスを処理します。
import { useChat, type ConnectionAdapter } from '@tanstack/ai-react' import type { UIMessage, ModelMessage, StreamChunk } from '@tanstack/ai' // カスタム Connection Adapter function createBedrockConnection(): ConnectionAdapter { return { async *connect( messages: UIMessage[] | ModelMessage[], _data?: Record<string, unknown>, abortSignal?: AbortSignal ): AsyncIterable<StreamChunk> { // メッセージを Bedrock 形式に変換 const chatMessages = messages.map((msg) => ({ role: msg.role, content: extractTextContent(msg), })) const response = await fetch('/api/chat', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ messages: chatMessages }), signal: abortSignal, }) const reader = response.body?.getReader() const decoder = new TextDecoder() let buffer = '' while (true) { const { done, value } = await reader!.read() if (done) break buffer += decoder.decode(value, { stream: true }) const lines = buffer.split('\n') buffer = lines.pop() || '' for (const line of lines) { if (line.startsWith('data: ')) { const data = JSON.parse(line.slice(6)) as StreamChunk yield data } } } }, } }
useChat フックの使用
カスタム Connection Adapter を useChat に渡して使用します。
function App() { const connection = useMemo(() => createBedrockConnection(), []) // TanStack AI の useChat フック const { messages, sendMessage, isLoading } = useChat({ connection, }) return ( <div> {messages.map((message) => ( <div key={message.id} className={message.role}> {message.parts.map((part, idx) => { if (part.type === 'thinking') { return <div key={idx} className="thinking">{part.content}</div> } if (part.type === 'text') { return <div key={idx}>{part.content}</div> } return null })} </div> ))} <form onSubmit={(e) => { e.preventDefault() sendMessage(input) }}> <input type="text" /> <button disabled={isLoading}>送信</button> </form> </div> ) }
実装にあたってのポイント(1)StreamChunk の形式
TanStack AI の useChat が正しく動作するためには、サーバーから返す SSE が以下の StreamChunk 形式に準拠している必要があります:
// ContentStreamChunk { type: 'content', delta: '新しい', content: '新しい', role: 'assistant', id, model, timestamp } // ThinkingStreamChunk { type: 'thinking', delta: '考え中...', content: '考え中...', id, model, timestamp } // DoneStreamChunk { type: 'done', finishReason: 'end_turn', id, model, timestamp } // ErrorStreamChunk { type: 'error', error: 'エラーメッセージ' }
この形式に準拠していれば、useChat は自動的にメッセージを UIMessage に変換し、thinking は ThinkingPart として、content は TextPart として管理されます。
実装にあたってのポイント(2)Extended Thinking(思考プロセス)のサポート
Claude Sonnet 4 / Opus 4 では Extended Thinking 機能が利用可能です。この機能を有効にすると、Claude が回答を生成する前の「思考過程」をストリーミングで取得できます。
// Thinking 有効時のレスポンス例 { type: 'thinking', delta: 'ユーザーは...', content: 'ユーザーは...' } { type: 'thinking', delta: 'について質問して', content: 'ユーザーは...について質問して' } { type: 'content', delta: 'こんにちは!', content: 'こんにちは!' } { type: 'content', delta: 'ご質問に', content: 'こんにちは!ご質問に' } { type: 'done', finishReason: 'end_turn' }
UI 側で thinking タイプのチャンクを別途表示することで、AI の思考過程を可視化できます。
ファイル添付のサポート
これだけだと面白くないので、ファイル添付をサポートしてみます。
こちらもサーバーサイドが TanStack AI の場合はカスタムが難しそうですが、今回はサーバについてはBedrockのSDKを利用しているだけなので、クライアント側でファイル情報を管理する変更がほとんどです。
なお、Bedrock では Claude 系のモデルの場合以下の形式をサポートしています。
| カテゴリ | 形式 |
|---|---|
| 画像 | JPEG, PNG, GIF, WebP |
| ドキュメント | PDF, CSV, DOC, DOCX, XLS, XLSX, HTML, TXT, MD |
1. 添付ファイルの管理
TanStack AI の sendMessage はテキストのみを受け取るため、添付ファイルは別途管理します。
// 添付ファイルの型定義 interface Attachment { type: 'image' | 'document' mediaType: string // 'image/png', 'application/pdf' など data: string // Base64 エンコード済みデータ name: string } function App() { const [pendingAttachments, setPendingAttachments] = useState<Attachment[]>([]) const attachmentsRef = useRef<Attachment[]>([]) // ... }
2. ref を使った添付ファイルの受け渡し
// カスタム Connection Adapter(添付ファイル対応) function createBedrockConnection(getAttachments: () => Attachment[]): ConnectionAdapter { return { async *connect(messages, _data, abortSignal) { const chatMessages = messages.map((msg, index) => ({ role: msg.role, content: extractTextContent(msg), // 最後のユーザーメッセージにのみ添付ファイルを付与 ...(msg.role === 'user' && index === messages.length - 1 ? { attachments: getAttachments() } : {}), })) // fetch でサーバーに送信... }, } } // 使用側 const connection = useMemo( () => createBedrockConnection(() => attachmentsRef.current), [] )
3. 送信時のタイミング制御
sendMessage を呼ぶ 前に attachmentsRef で管理するファイルを送信します。
const handleSendMessage = async () => { // 送信前に attachmentsRef を設定(connect 関数から参照される) attachmentsRef.current = [...pendingAttachments] // UI 表示用に保存 setAttachments((prev) => [...prev, ...pendingAttachments]) // 入力をクリア setInput('') setPendingAttachments([]) // メッセージ送信(この時点で connect が呼ばれ、attachmentsRef を参照) await sendMessage(messageText) // 送信完了後にクリア attachmentsRef.current = [] }
4. サーバ側での添付
サーバー側では、添付ファイルを追加する formatMessages関数を設け、Converse API に渡す前にメッセージを整形します。
private formatMessages(messages: ChatMessage[]): BedrockMessage[] { return messages.map((msg) => { const content: ContentBlock[] = [] // テキストコンテンツ if (msg.content) { content.push({ text: msg.content }) } // 添付ファイル if (msg.attachments) { for (const attachment of msg.attachments) { if (attachment.type === 'image') { content.push({ image: { format: this.getImageFormat(attachment.mediaType), source: { bytes: Buffer.from(attachment.data, 'base64') }, }, }) } else if (attachment.type === 'document') { content.push({ document: { format: this.getDocumentFormat(attachment.mediaType), name: sanitizeDocumentName(attachment.name), source: { bytes: Buffer.from(attachment.data, 'base64') }, }, }) } } } return { role: msg.role, content } }) }
デモ
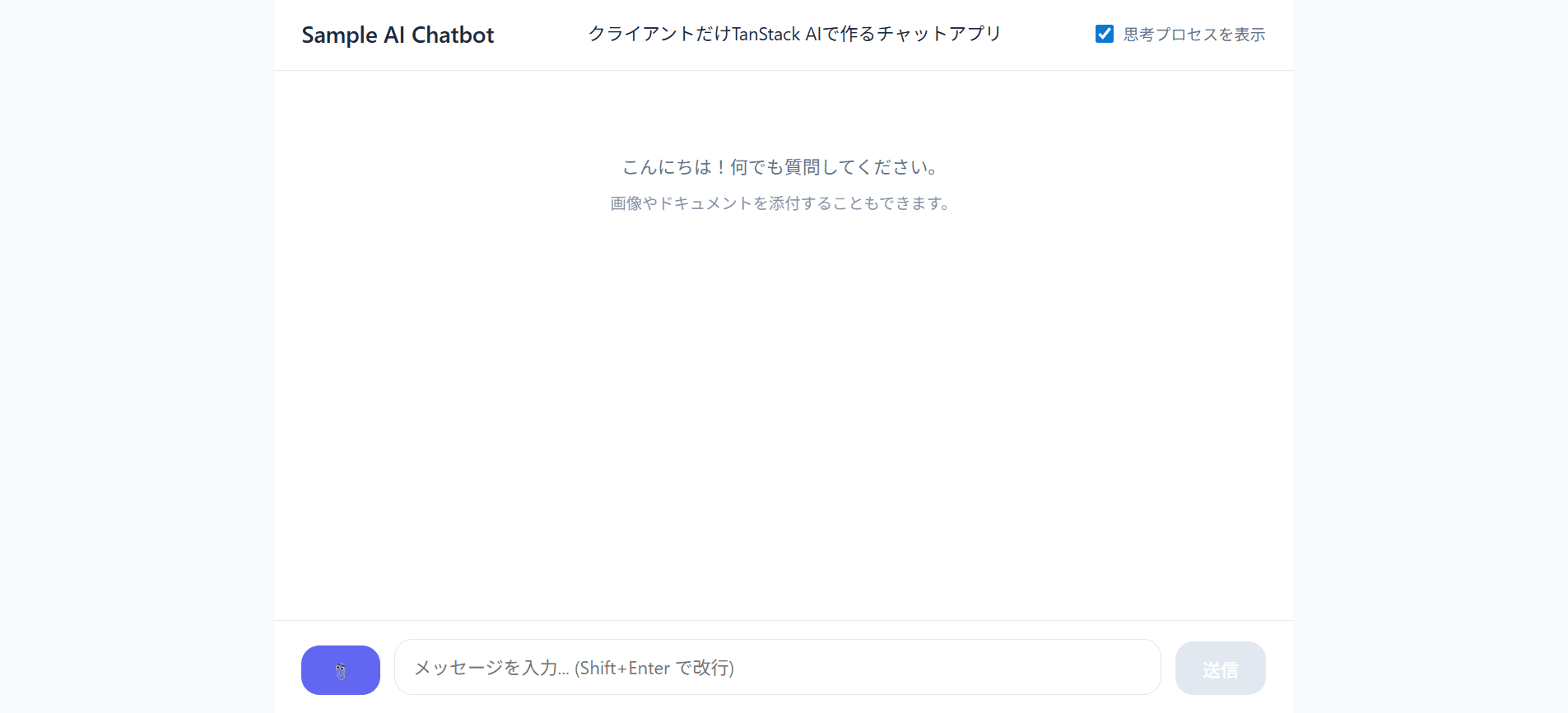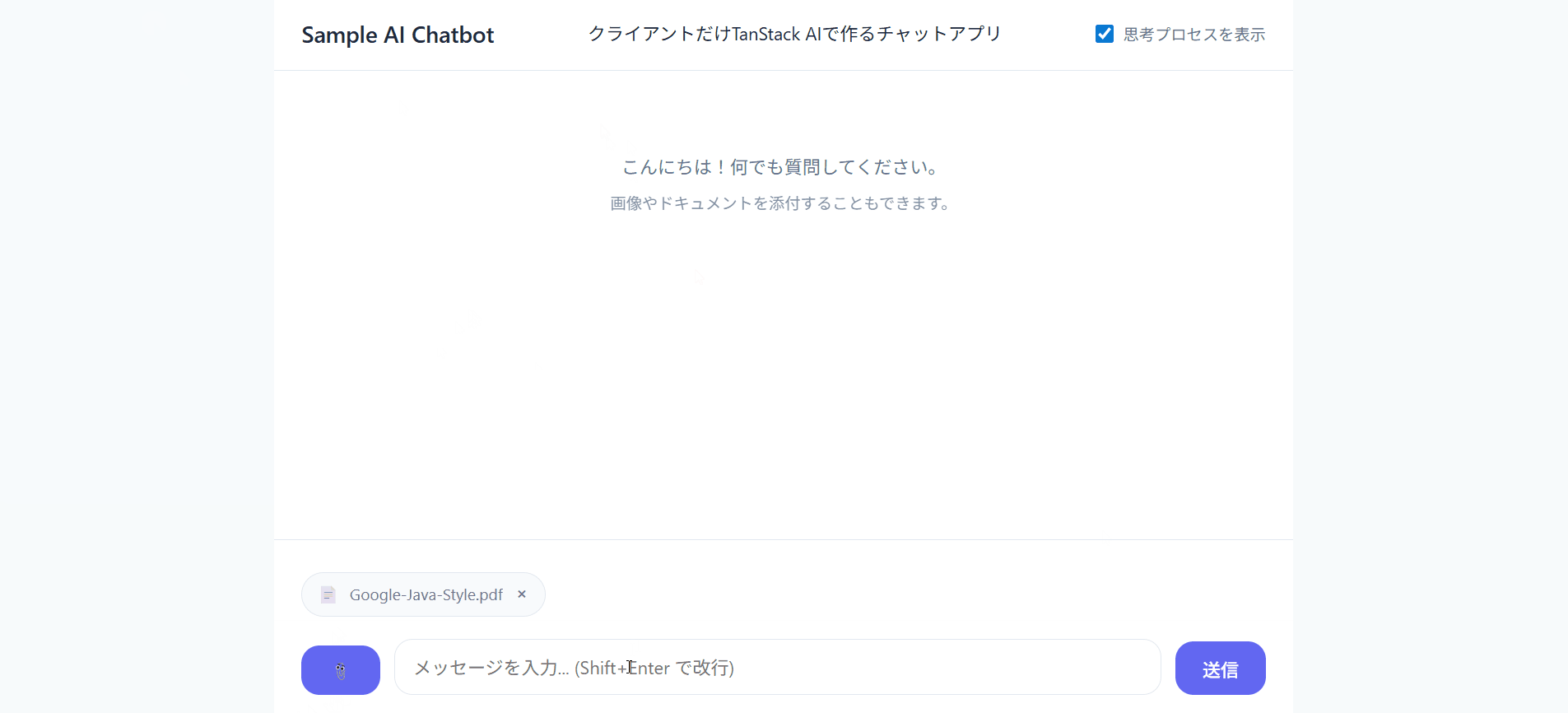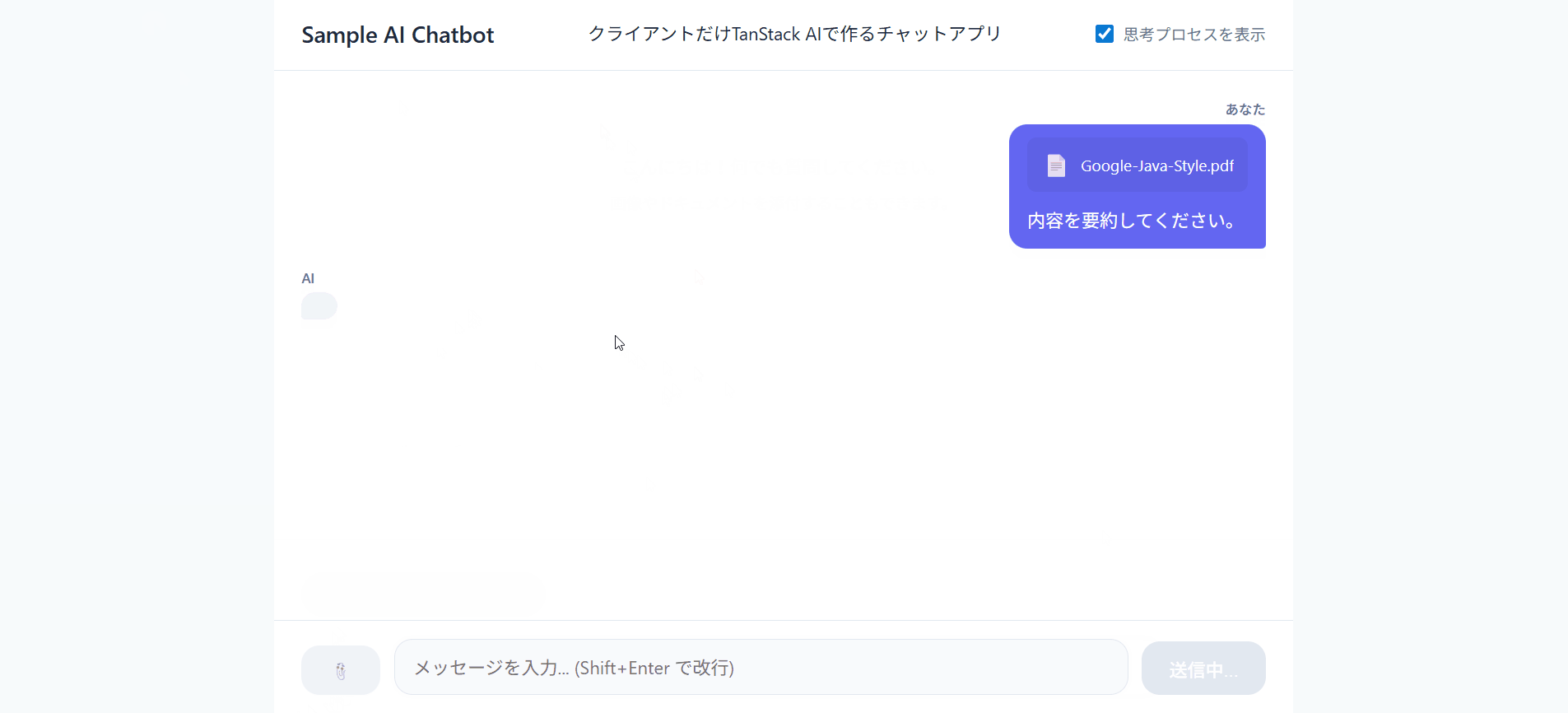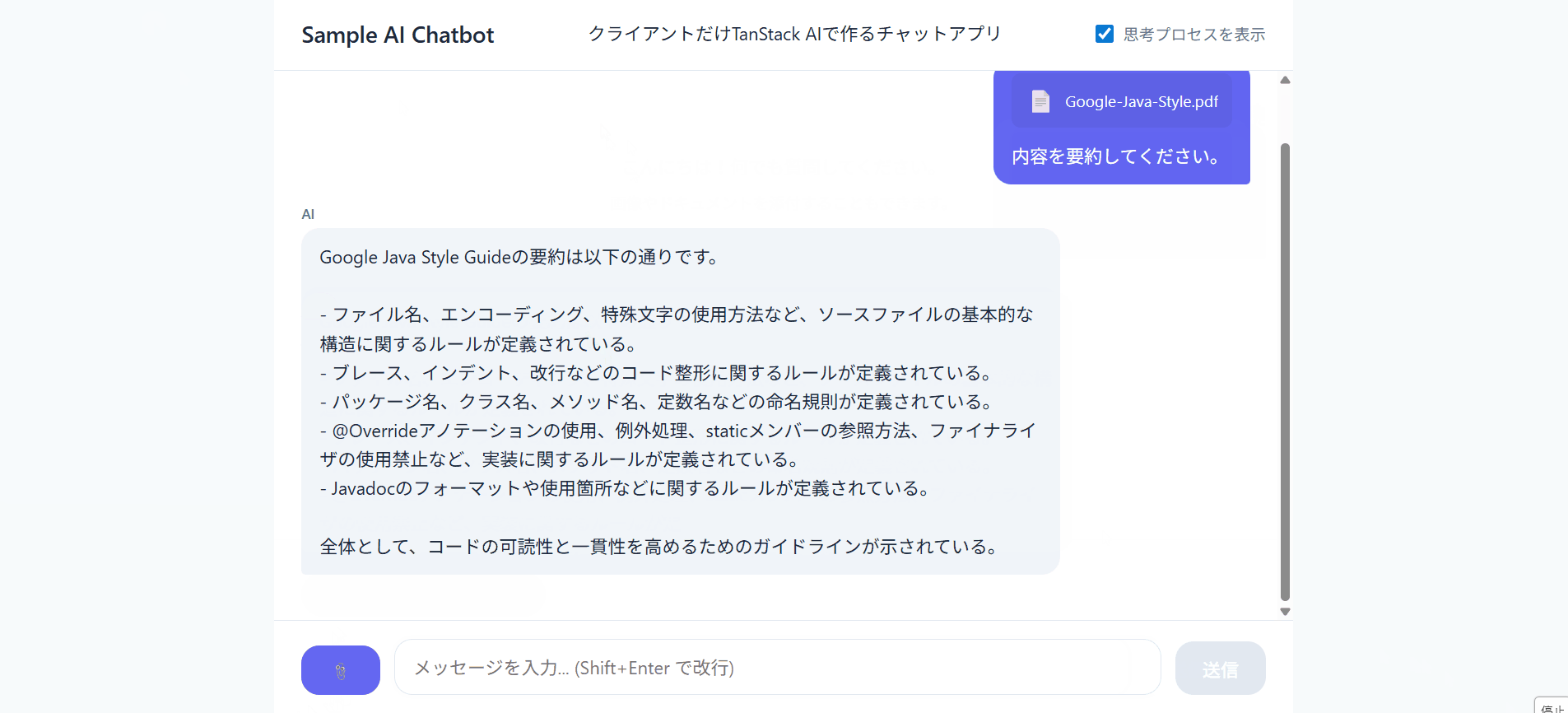
まとめ
TanStack AI と Amazon Bedrock を組み合わせることで、以下のメリットが得られます
カスタムアダプターの実装は手間がかかりますが、TanStack AI の設計思想(AsyncGenerator パターン、StreamChunk 型)に従えば比較的シンプルに実装できます。
TanStack AI はまだアルファ版ですが、将来的には公式で Bedrock アダプターがサポートされる可能性もあります。それまでは、今回紹介したようなカスタムアダプターで対応できます。
ただし結論として、現時点で Bedrock等公式に接続が提供されていないAI基盤を利用する場合はVercel AI SDKを利用したほうが簡潔な構成にできます。
TanStack AIの一番の課題として、接続先のアダプタを自前で構える必要がある点が現時点でかなりのボトルネックとなります。
しかし、Vercel エコシステムにロックインされてしまわないためにも、TanStack AI の今後の進歩には期待しています。
以上、拝読ありがとうございました。
私たちは一緒に働いてくれる仲間を募集しています!
電通総研 キャリア採用サイト執筆:@kamino.shunichiro
レビュー:Ishizawa Kento (@kent)
(Shodoで執筆されました)



