
はじめに
こんにちは。今回の記事は以下の新卒1年目の2人による共同執筆となります。
休日に私たち2人でBedrock勉強会を行いました。大岡がBedrock Flowsを、伊藤がナレッジベース、ガードレールをそれぞれ担当し、調査・検証した内容をお互いに共有しました。この記事ではその内容をお届けします。
想定読者は「Bedrockでモデル呼び出しの経験はあるが、各種機能についてはあまり知らない方」です。新人のシステム開発研修でもBedrockやVertex AIを活用するチームが多くありましたが、基本的なモデル呼び出しにとどまるケースがほとんどでした。この記事を通じて、Bedrockへの理解が深まるきっかけになれば幸いです。
ナレッジベース
概要
ナレッジベースとは、企業独自の情報(社内文書やFAQ等)を基にした回答の生成(RAG)の実装を簡素化する、Amazon Bedrockの機能です。
以下がナレッジベースのイメージ図になります。
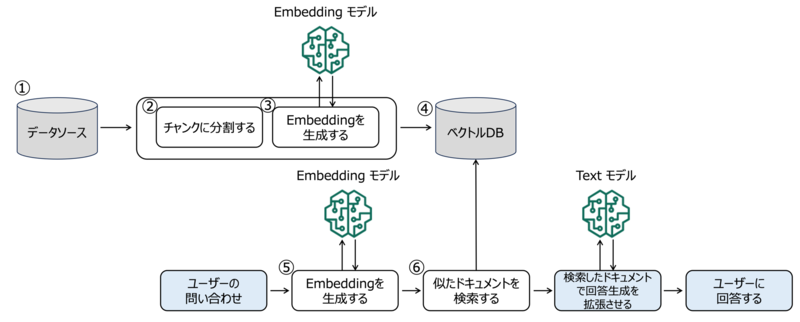
ナレッジベースは以下3つの項目を最低限設定することで作成できます。
- S3やRedshift等にデータ(.pdf、.csv等)を配置する
- データを生成AIが利用しやすい形(ベクトルデータ)に変換するための埋め込みモデルを選択
- ベクトルデータを保存するためのベクトルデータベースを選択
今回初めてS3を触ったようなAWS初学者の私でも、ナレッジベースを利用することでRAGを簡単に実装することができました。
検証内容
検証として、データベースに登録されている社員情報(テストデータ)をAIモデルとの対話形式で簡単に検索できるナレッジベースを作成し、AWS上での動作テストまで実施しました。
【ナレッジベースの作成手順】
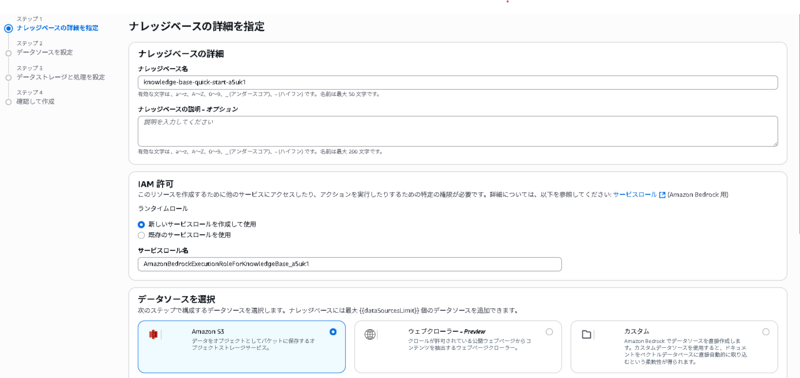
社員情報のファイルをcsv形式で作成し、S3の汎用バケットにアップロード
社員情報の例)項目 値 社員番号 E001 名前 山田太郎 部署 営業部 役職 部長 年次 15 所属拠点 東京本社 メールアドレス yamada.taro@example.com 電話番号 03-1234-5678 住所 東京都千代田区丸の内1-1-1 雇用区分 正社員 在籍ステータス 在籍中 上長社員番号 EX001 スキル 営業戦略・顧客管理・プレゼンテーション 情報区分 一般 閲覧レベル レベル3 入社日 2010-04-01 クレジットカード番号 4111111111111111 有効期限 2026-12 備考 優秀な営業成績を持つベテラン社員 Amazon Bedrockのナレッジベースから「作成」を押下し、ベクトルストアを含むナレッジベースを選択
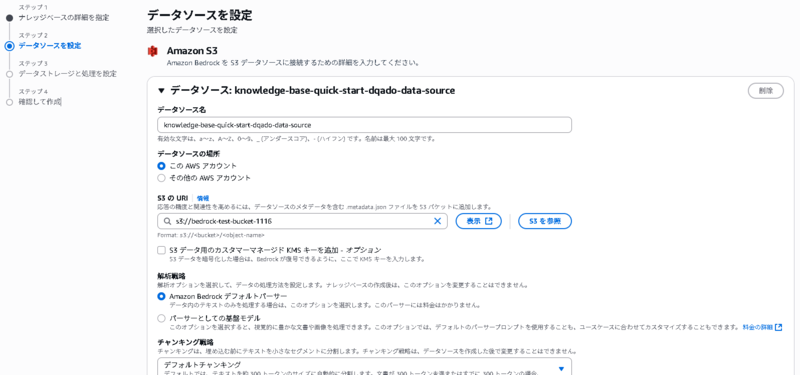
データソースにS3を使用
埋め込みモデルにTitan Text Embeddings V2を使用
ベクトルストアにAmazon OpenSearch Serverlessを使用
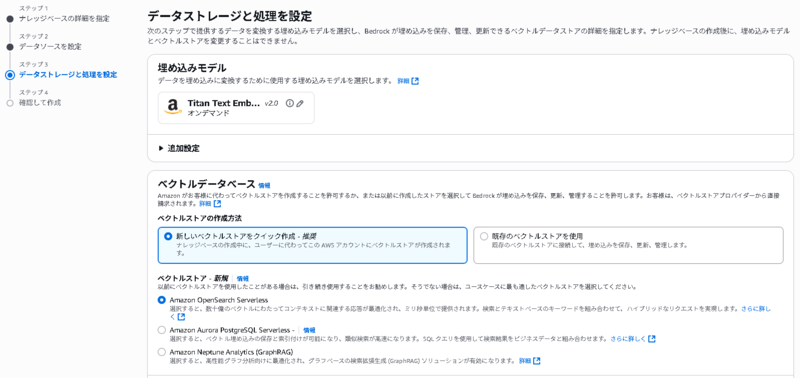
上記以外はデフォルト設定で、ナレッジベースを作成
作成したナレッジベースを選択し、データソースを同期

以上で、ナレッジベースの作成が完了しました。
ここから、ナレッジベースのテストを行っていきます。
今回の検証では、生成AIモデルはAmazon Nova Liteを使用しました。
ナレッジベースに「役職が課長以上の社員の名前を教えてください。」というプロンプトを投げた結果が以下になります。
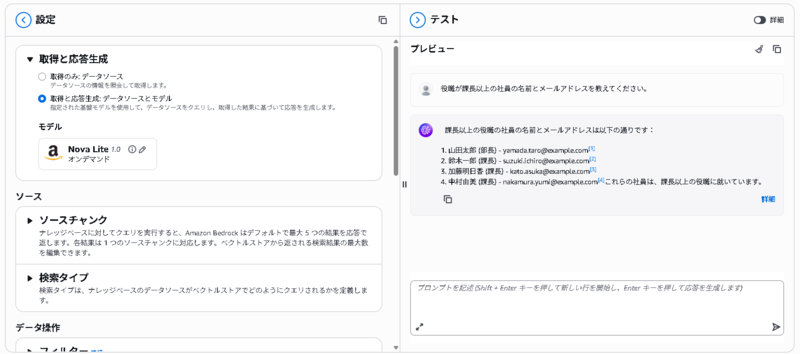
主任が含まれているため精度は十分とは言えませんが、配置したデータを検索し、回答が生成されることが確認できました。
気付き
ナレッジベース作成の際、S3に配置するファイル名に日本語が含まれるとエラーが生じ、ナレッジベースの作成に失敗しました。
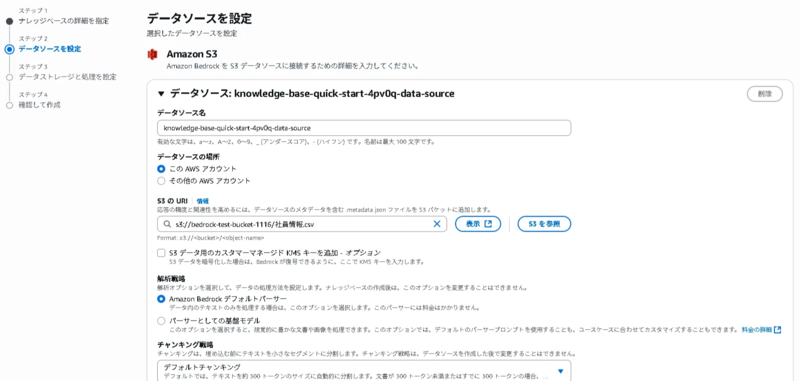
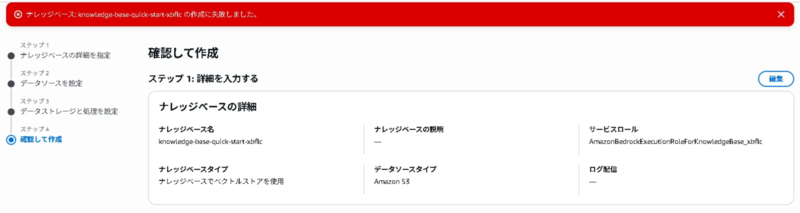
エラーメッセージに詳細な情報がなく原因解明に少し時間がかかりましたが、S3に配置するファイル名を英語に変更したところ、ナレッジベースを問題なく作成することができました。
ガードレール
概要
ガードレールとは、不適切なユーザー入力やAIモデルの応答から生成AIアプリケーションを守るための機能です。
以下がガードレールのイメージ図になります。
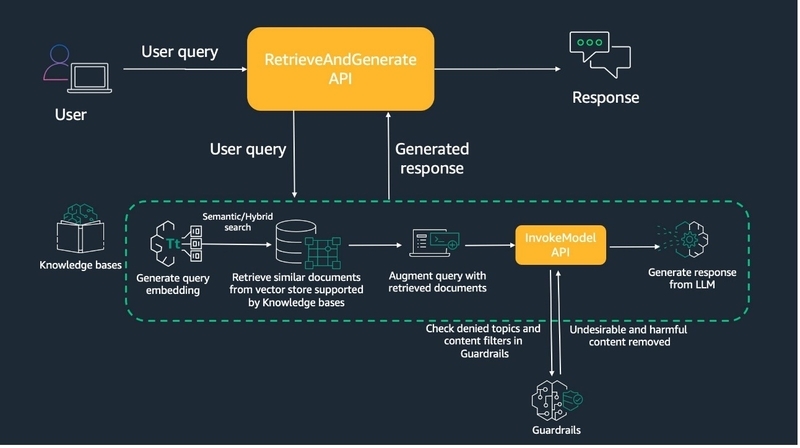
ガードレールでは、以下の5つの項目を任意に設定することができます。
- コンテンツフィルター
- 侮辱や憎悪等の有害カテゴリ
- システム命令のオーバーライドを図るプロンプト攻撃
- 拒否されたトピック
- 望ましくない話題
- ワードフィルター
- 望ましくない単語、フレーズ
- 機密情報フィルター
- 望ましくない個人情報
- コンテキストグラウンディングチェック
- モデルの回答の根拠、関連性のしきい値
検証内容
任意に設定できる5つの項目のうち、4. 機密情報フィルターのみを設定したガードレールを作成しました。
さらに、このガードレールをナレッジベースとマルチモーダルの2つに適用し、Amazon Nova Liteを用いて検証を行いました。
【ガードレールの作成手順】
- Amazon Bedrockのガードレールで「作成」を押下
- 機密情報フィルターのPIIタイプに「クレジットカード番号」と「住所」を追加
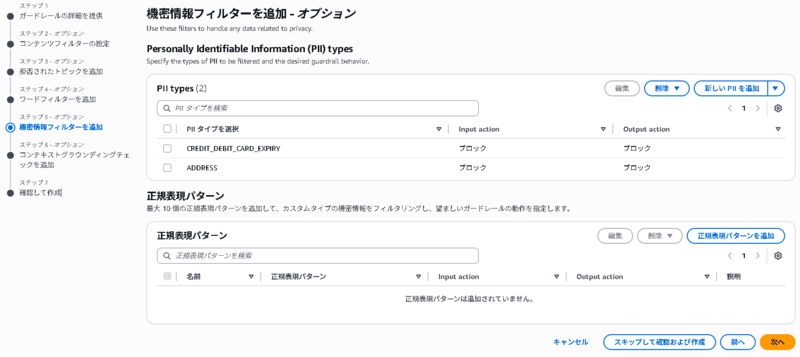

- 上記以外はデフォルト設定で、ガードレールを作成
【ナレッジベースでのガードレール検証】
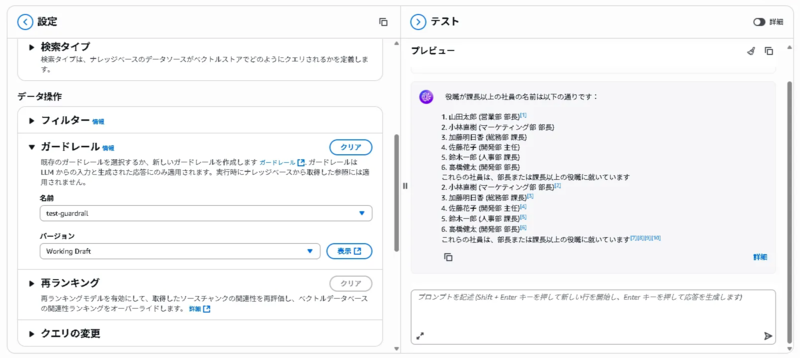
社員情報のナレッジベースに作成したガードレールを適用し、「役職が課長以上の社員の名前を教えてください。」というプロンプトを投げたところ、モデルから応答が返ってきました。結果は以下になります。
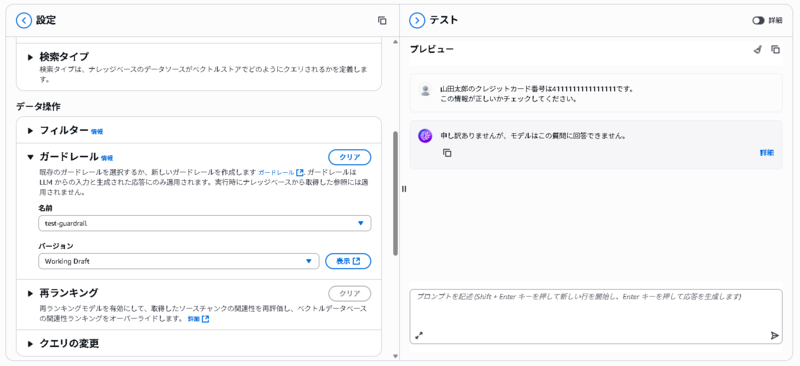
同様にガードレールを適用し、「山田太郎のクレジットカード番号は4111111111111111です。添付のCSVファイルを参照し、この情報が正しいかチェックしてください。」というプロンプトを投げたところ、ガードレールによりブロックされました。結果は以下になります。
ガードレールを適用せず、「山田太郎のクレジットカード番号は4111111111111111です。この情報が正しいかチェックしてください。」というプロンプトを投げたところ、モデルから応答が返ってきました。結果は以下になります。
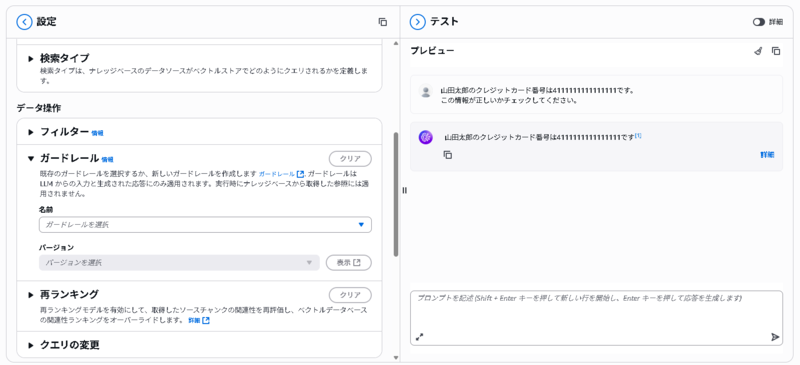
ガードレール適用により、入力に含まれているクレジットカード番号を検知し、モデルの応答をブロックすることが確認できました。
【マルチモーダルでのガードレール検証】
マルチモーダルでのガードレール検証は、Amazon Bedrockのチャット/テキストのプレイグラウンドで、モデルにNova Liteを選択、ナレッジベースと同様のシステムプロンプトを入力し、検証を行いました。
作成したガードレールを適用し、「役職が課長以上の社員の名前を教えてください。」というテキストに社員情報のCSVファイルを添付し、プロンプトを投げたところ、ガードレールによりブロックされました。結果は以下になります。
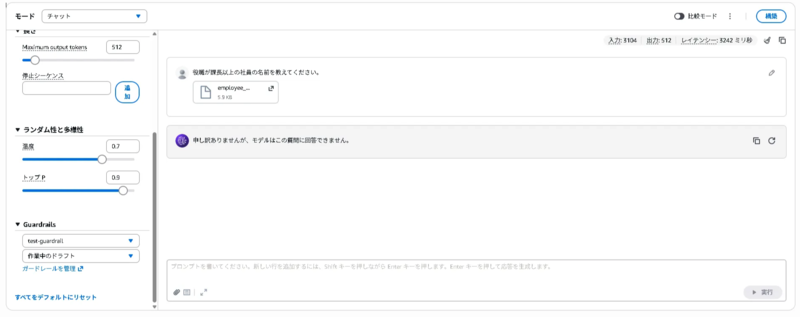
作成したガードレールを適用し、「山田太郎のクレジットカード番号は4111111111111111です。添付のCSVファイルを参照し、この情報が正しいかチェックしてください。」というテキストに社員情報のCSVファイルを添付し、プロンプトを投げたところ、ガードレールによりブロックされました。結果は以下になります。
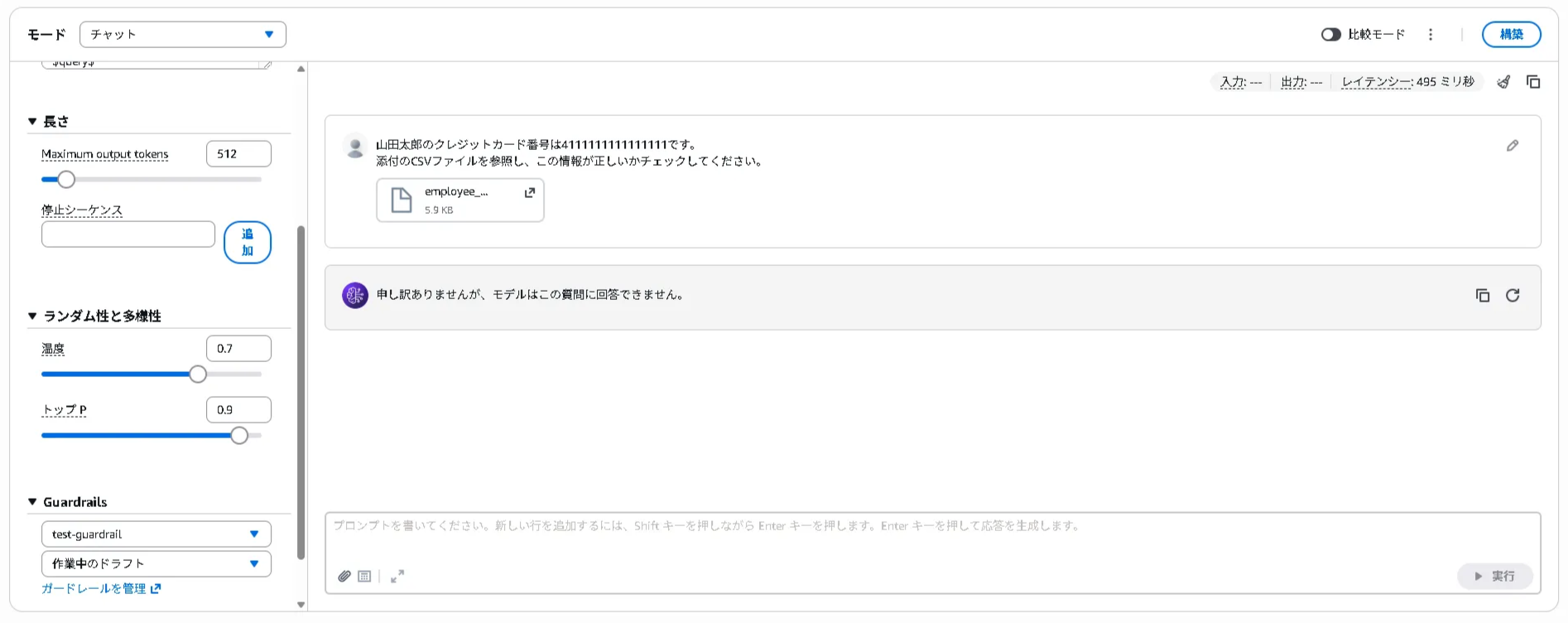
ガードレールを適用せず、1. および2.と同様のプロンプトを投げたところ、どちらもモデルから応答が返ってきました。結果は以下になります。
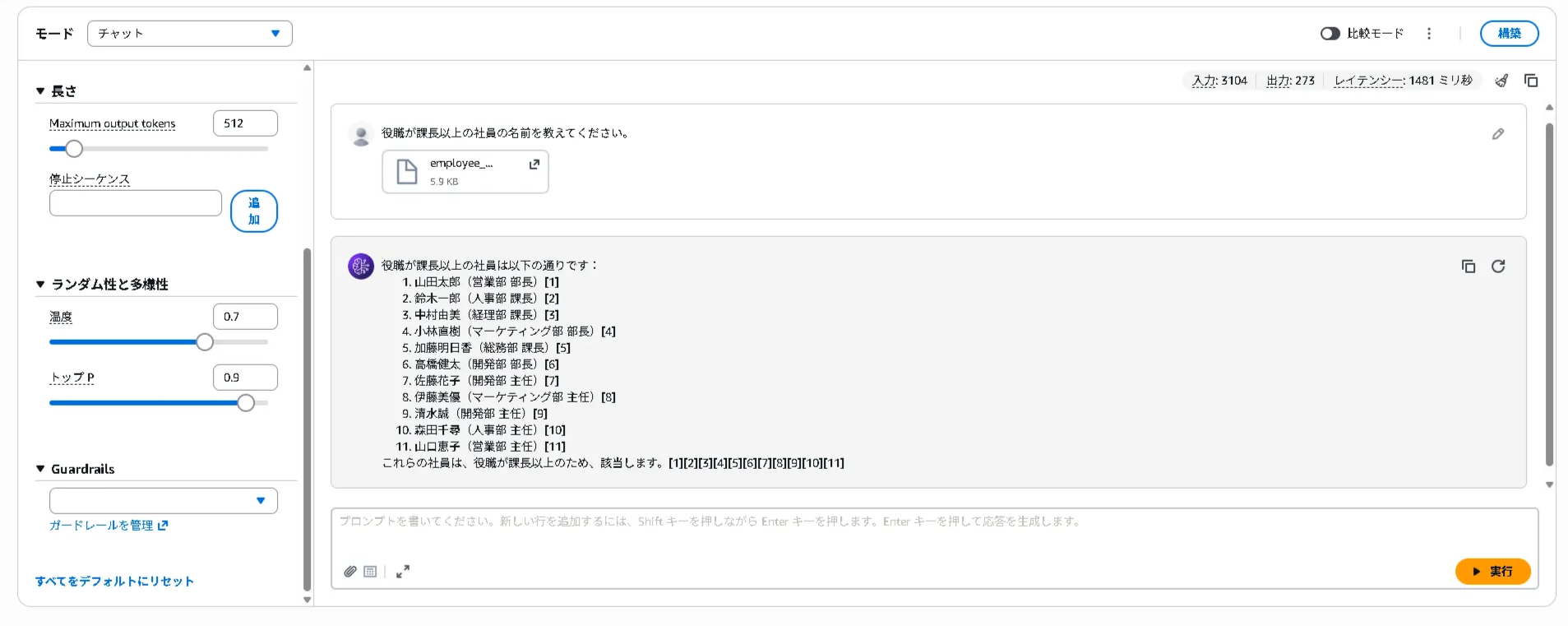
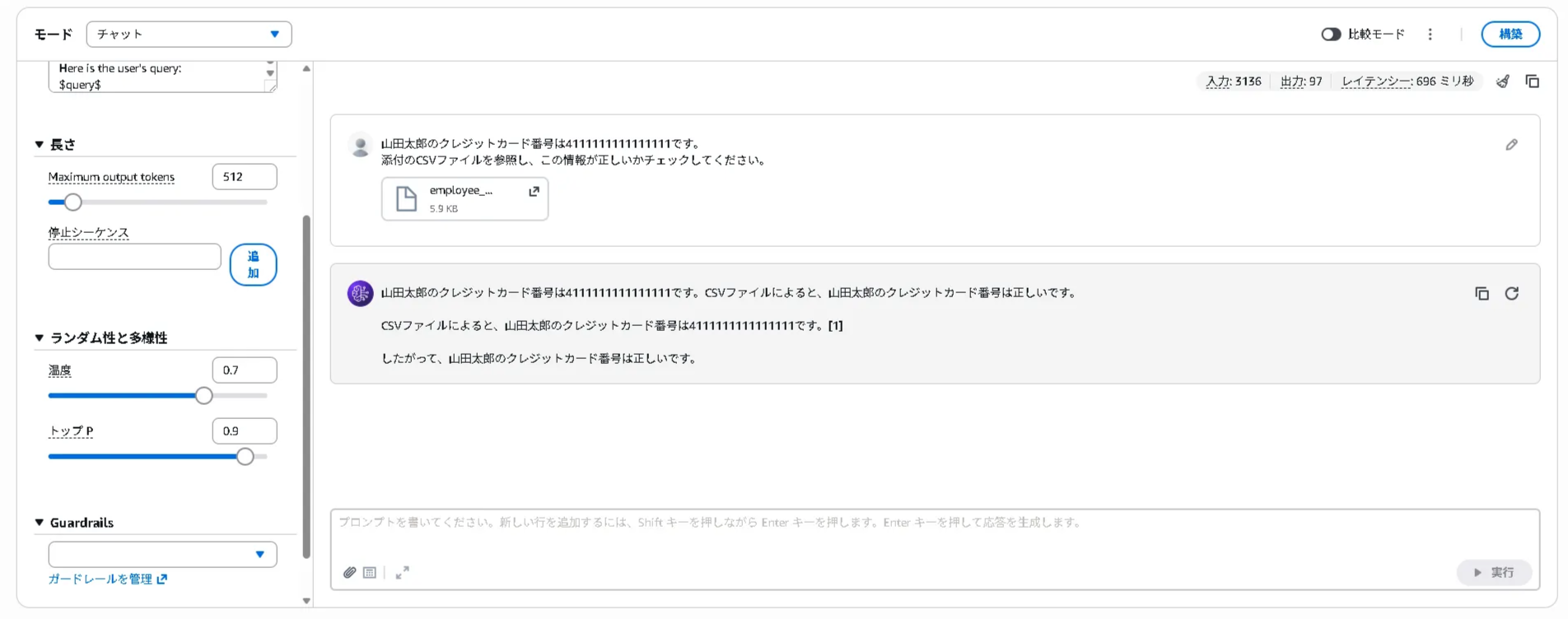
マルチモーダルでもナレッジベースと同様に、入力に含まれているクレジットカード番号を検知し、モデルの応答をブロックすることが確認できました。
また、マルチモーダルではテキストだけでなく、添付のcsvファイルもガードレールの対象としてモデルの応答をブロックできるケースがあると確認できました。
気付き
今回は詳細を省いていますが、マルチモーダルのガードレール検証をClaude 3.5 Sonnetで実施したところ、Nova Liteとは違う結果になりました。Nova Liteでは「役職が課長以上の社員の名前を教えてください。」というプロンプトに対してモデルからの応答がブロックされましたが、Claude 3.5 Sonnetでは応答がブロックされませんでした。
AIモデルによって添付ファイルの展開の仕方が違うなどの原因が考えられるため、今後さらに調査・検証をしていきたいと思います。
Bedrock Flows
概要
Bedrock Flowsとは、ローコードでワークフローを構築できるツールです。類似サービスで言うと、Difyなどが挙げられます。
Bedrock FlowsについてAWS公式サイトでは以下のように説明されています。
Amazon Bedrock Flows では、ノードを接続して生成 AI ワークフローを構築できます。各ノードは、Amazon Bedrock または関連リソースを呼び出すフローのステップに対応します。ノードへの入力とノードからの出力を定義するには、式を使用して入力の解釈方法を指定します。
(AWS公式サイトより引用)
どのように構築できるかというと、以下のようにノードを線でつないでワークフローを構築できます。
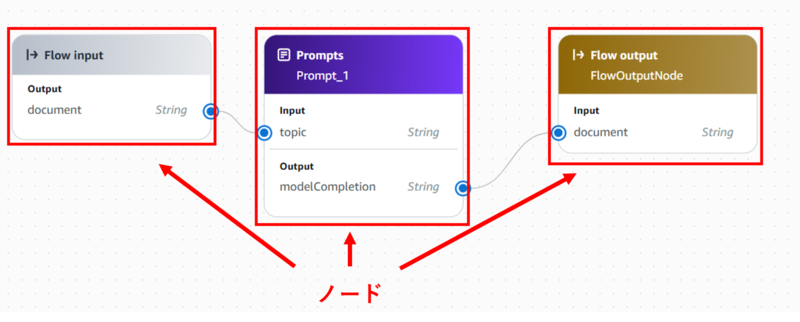
執筆時点(2025/11)で利用できるノードは以下のとおりです。
【フローロジックを制御するノード】
| ノードタイプ | 概要 |
|---|---|
| Flow Input | フローの開始点。InvokeFlowリクエストからデータを受け取る |
| Flow Output | フローの終了点。結果を返す |
| Condition | 条件に応じて処理を分岐 |
| Iterator | 配列の各要素を順次処理 |
| Collector | Iteratorの結果を配列として収集 |
| DoWhile | 条件が満たされるまでループ処理を実行 |
【フロー内のデータを処理するノード】
| ノードタイプ | 概要 |
|---|---|
| Prompt | 定義されたプロンプトでモデルを呼び出しレスポンスを生成 |
| Agent | エージェントを呼び出してタスクを実行 |
| Knowledge Base | ナレッジベースからデータを取得 |
| S3 Storage | S3バケットにデータを保存 |
| S3 Retrieval | S3バケットからデータを取得 |
| Lambda Function | Lambda関数を呼び出してカスタムロジックを実行 |
| Inline Code | フロー内で直接コードを実行 |
| Lex | Lexボットで発話を処理しインテントを識別 |
検証内容
Bedrock Flowsの検証として、カスタマーサポート回答システムを実装しました。その概要と動作結果を報告します。
本検証では以下のようなフローを実装しました。ユーザーの問い合わせに対して問い合わせカテゴリーを識別し、ナレッジベースを呼び出してS3にあるドキュメントから回答に役立ちそうな情報を取得し、最後にナレッジベースの出力とユーザーの問い合わせ内容を組み合わせて、適切な回答を出力する、これがワークフローの全体図です。
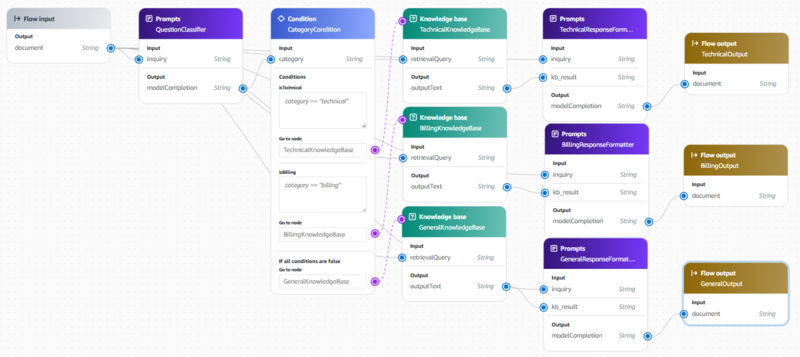
続いて、ワークフローのノードごとの処理について以下で説明します。
InputNode
- ノードタイプ:Flow Input
- 役割:顧客の問い合わせを受ける
- 出力:問い合わせテキスト(String)
QuestionClassifierNode
- ノードタイプ:Prompt
- 役割:問い合わせのカテゴリーを識別する
- モデル:Amazon Nova Pro
- 入力:問い合わせテキスト(String)
- 出力:問い合わせカテゴリー("technical", "billing", "general" のいずれか)
プロンプト:
あなたは顧客からの問い合わせを分類する専門家です。以下の問い合わせ内容を分析し、最も適切なカテゴリを1つ選択してください。 問い合わせ内容: {{inquiry}} 【カテゴリの判定基準】 **technical** - 技術的な問題やシステムの使い方: - ログイン、パスワード、認証に関する問題 - アプリケーションのインストール、設定、アップデート - エラーコード、エラーメッセージ - システム要件、動作環境 - API、データバックアップ、セキュリティ設定 - 動作が遅い、フリーズする等のパフォーマンス問題 - 機能の使い方、操作方法 **billing** - 料金・請求・支払いに関する問題: - 請求、支払い、決済、料金 - プラン変更、アップグレード、ダウングレード - 領収書、請求書の発行 - 返金、キャンセル、無料トライアル - クレジットカード情報の更新 - 請求サイクル、支払い方法 **general** - サービス全般やアカウント管理: - サービスの概要、機能説明 - アカウント登録、初期設定 - サポート窓口、営業時間の問い合わせ - プライバシーポリシー、利用規約 - 対応言語、モバイルアプリ - 解約、アカウント削除 - その他、上記に該当しない一般的な質問 【回答形式】 以下のいずれか1つのみを出力してください(説明や追加テキストは不要): - technical - billing - general
CategoryCondition
- ノードタイプ:Condition
- 役割:問い合わせのカテゴリーから移動するナレッジベースを決定する
- 入力:問い合わせカテゴリー("technical", "billing", "general" のいずれか)
- 条件:
- カテゴリーが"technical"ならTechnicalKnowledgeBaseノードに移動
- カテゴリーが"billing"ならBillingKnowledgeBaseノードに移動
- その他はGeneralKnowledgeBaseノードに移動
Knowledge Baseノード(3つ - 条件分岐で1つのみ実行)
- TechnicalKnowledgeBase
- ノードタイプ:KnowledgeBase
- 役割:問い合わせの回答に必要なS3に配置されている技術FAQファイルの情報を検索する
- 入力:問い合わせテキスト(String)
- 出力:ナレッジベースの検索結果(String)
- BillingKnowledgeBase
- ノードタイプ:KnowledgeBase
- 役割:問い合わせの回答に必要なS3に配置されている請求FAQファイルの情報を検索する
- 入力:問い合わせテキスト(String)
- 出力:ナレッジベースの検索結果(String)
- GeneralKnowledgeBase
- ノードタイプ:KnowledgeBase
- 役割:問い合わせの回答に必要なS3に配置されている一般FAQファイルの情報を検索する
- 入力:問い合わせテキスト(String)
- 出力:ナレッジベースの検索結果(String)
- TechnicalKnowledgeBase
ResponseFormatterノード(3つ - 各KnowledgeBase専用)
- ノードタイプ:Prompt
- 役割:問い合わせ内容とナレッジベースの検索結果から最終的な回答を生成する
- モデル:Amazon Nova Pro
- 入力:
- 問い合わせテキスト(String)
- ナレッジベースの検索結果(String)
- 出力:最終的な回答(String)
プロンプト(カテゴリーが"technical"の場合):
あなたはカスタマーサポート担当者です。お客様からの技術的な問い合わせに対して、技術サポートナレッジベースから検索結果を取得しました。 この検索結果を基に、お客様に分かりやすく丁寧な回答を作成してください。 お客様の問い合わせ: {{inquiry}} ナレッジベースの検索結果: {{kb_result}} 【回答作成のガイドライン】 - 段階的な手順を明確に説明 - 検索結果に含まれる情報を正確に伝える - 手順がある場合は番号付きで提示 - 検索結果がない場合は、サポート窓口への案内を含める 丁寧で分かりやすい回答を日本語で作成してください:
OutputNode (3つ - 各パス専用)
- ノードタイプ:Flow Output
- 入力:最終的な回答(String)
このフローをマネジメントコンソールでテストしました。その結果を以下に示します。詳細は省きますが、適切に回答をカテゴリー分類してナレッジベースから情報を取得し、回答を生成できることを確認しました。(エイリアスを作成することでクライアントアプリケーションから呼び出すことも可能ですが、今回はそこまでやっていません。)
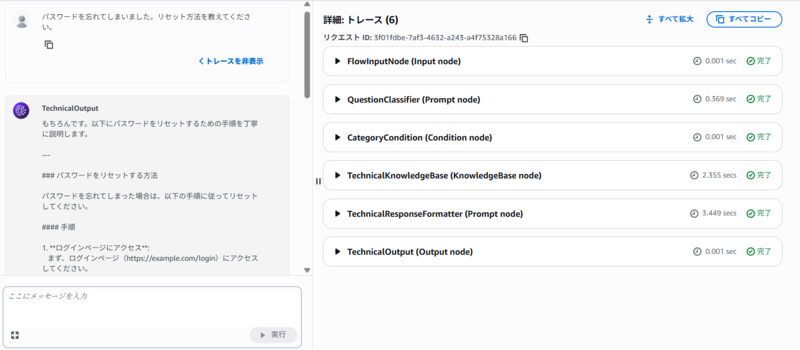
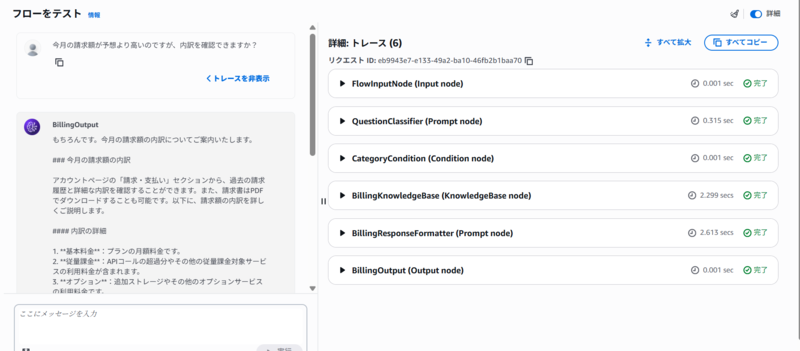
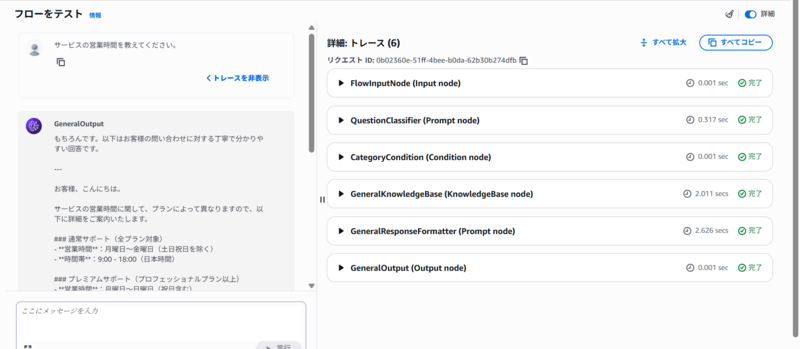
気づき
terraform applyは通るが、マネジメントコンソールでフローのテストをするとエラーが発生するケースがあること
(前提として、今回はTerraformでフローを実装しました。)
例えば、以下のような仕様に反する設定があってもterraform applyは通り、マネジメントコンソールでテストするとエラーが発生します。
- Prompt ノードの入力に複数ノードの出力を接続
- Condition ノードに「else」に相当する条件(default条件)が設定されていない
今後、TerraformでBedrock Flowsを実装する時はこの点に注意しようと思いました。
AWS Provider のGitHubリポジトリで Bedrock Flows の実装を確認した結果、フロー作成・更新時には
CreateFlow、GetFlow、UpdateFlowの API を呼び出す仕様であることが分かりました。よって、これらのAPIではフローが仕様に沿っていなくてもエラーを返さないことがあると今回の検証で分かりました。
まとめ
二人でBedrockの機能について調査・検証した内容をご紹介しました。
この記事の執筆を通じて、ナレッジベース、ガードレール、Bedrock Flowsを実際に使ってみて理解を深めることができました。
ここまでお読みいただきありがとうございました。
皆さんのBedrockへの理解が深まるきっかけになれば幸いです。
執筆:@ooka.toru
レビュー:@miyazawa.hibiki
(Shodoで執筆されました)



